










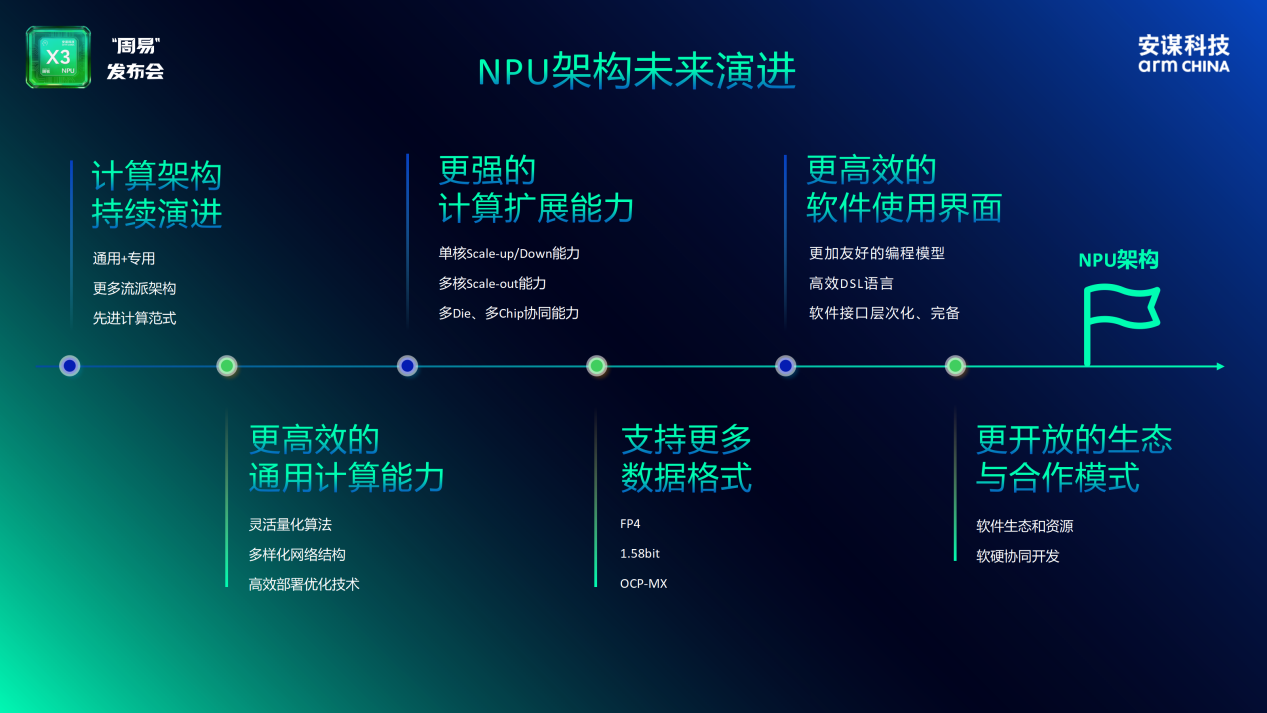
����AI������ƶ˹㷺�³����豸��Ե���˲�AI�������ӵ�һ��֪�����Ӷ�ģ̬��������̱���һ�����Եײ����������ǰ��δ�е�Ҫ���������Ǽ��������������ǶԼ���Ч�ʡ���Ч������ϵͳ�Ż����ռ����顣�ڴ˱����£��칹�����Ϊ��Ȼѡ��NPU��ΪרΪAI���Ƶļ��㵥Ԫ������ĵ�λ�����ԡ�
���գ���ı�Ƽ�Arm China��ʽ����������һ��NPU IP�����ס�X3���ò�Ʒ����һ�μĵ������������Ǵӵײ�ܹ���Ϊ�˲��ģ���������Ƶĸ���֮������ּ����Arm CPU��GPUЭͬ������һ��������Ч�������칹����������ֱָ��ǰ�˲�AI�ڲ����ģ��ʱ���ٵ���������������Ч�ȶ���ʹ�㡣

һ���ܹ�������DSP+DSA˫����赣���ʤ��ģ����Ч
�����ס�X3�ĺ���ͻ����������õ�����DSP+DSA�ܹ�����һרΪ��ģ����Ƶļܹ���ʵ���˴Ӷ�����㵽�������Ĺؼ���Խ��Ϊ����ģ���ṩ�˸��ߵľ��ȺͶ�̬��Χ��
�����ס�X3���������ָ��������Ŀ���������棬��Cluster���ṩ�ߴ�8-80 FP8 TFLOPS������������á��������棬��Core�����ߴ�256GB/s����Ч��������Լ��ģ�����еġ��ڴ�ǽ��ƿ�������⣬�����ס�X3֧��W4A8/W4A16�ȶ˲��ģ�����бر�����������ģʽ��������������Ч�����ܶȡ�
��Ϊֵ��һ����ǣ������ס�X3���������е�Ӳ����ѹ����WDC���ü����ܶԾ�����������ѹ���Ĵ�ģ��Ȩ�ؽ���Ӳ����ѹ���Ӷ�������Լ15%�ĵ�Ч��������������һ�����˼�ġ��������ݡ�������

����ϵͳ�Ż��������أ��ͷŶ˲�AI������DZ��
����ǿ��ļ���������������ƣ������ס�X3��ϵͳ���Ż�����ʵ������Ҫ������Ծ���伯�ɵ�AIר��Ӳ������AIFF��ר��Ӳ��������Эͬ������������һ��Ч���칹����ܹ����ܹ���CPU�ӷ��ص�AI��������н�ų���������ظ��ش��������0.5%�ļ���ˮƽ��ͬʱʵ���뼶�ij��͵����ӳ١�
����ϵͳ���Ż�����������ֱ���������ڣ������ء����ס�X3���ն��豸��Ҫ���д�������ʶ�𡢻�����֪��ͼ�����ȶ���AI����ʱ����������֮���ܹ�ʵ�־�����Դ���������л����û���ʵ��ʹ���м������ܲ����κο��ٻ��ӳ٣�ϵͳ��Ӧʼ�ձ��ָ�Ч���������֡��С�ȴǿ��Ķ�����AI���飬���ǡ����ס�X3��ϵͳ�ܹ�����ϵ�ͻ��������Ķ��ؼ�ֵ��Ҳ�ö˲����ܵ������ռ���ǰ������һ��
�������Ĵ����������˲�AI��ģ������
ƾ��������Ч�ȡ������ܶ���ͨ���Եȷ�����ۺ����ƣ������ס�X3��Ϊ��һ��AI����оƬ��������Ϊ������ʩ�������������ƶ��նˡ��������������Ĵ�ؼ������ṩǿ�ɿ��ĺ���AI����֧�š�
�ھ���Ӧ���У������ס�X3�ܹ���Ч�����Ӹ��ӵ��ƶ�������ʵʱ��Ҫ�ߵı�Ե�����������磬������������������ͬʱ������֧�ֶ�·��������ͷ���л�����֪�ͼ�ʻԱ״̬��أ��������������ˣ��������ð�������ͷ�߱�����������ʶ������Ϊ�����������������ܼҾ��豸ʵ�ָ���Ȼ���������������ķ�������ս���� ͼʮ����ȷ������Ҫͨ����ͻ���Ե�Ӳ���ܹ����������������������Ż���������˲�AI�ڼ���Ч�ʡ����Ŀ��Ƽ��ɱ�Ч���ϵ�ȫ����ҵ��ˡ�

��Ϊ��ı�Ƽ���ս�Ժ��IJ�Ʒ�������ס�NPU���з���֧��100%�����й������Ŷӣ������ѳɹ����������Ʒ�����������ļ������г����顣�ڵ�ǰ�й��ѳ�Ϊȫ��˲�AI�����������ͷ���ı����£������ס�X3���Ƴ�������Armȫ����̬ϵͳ������ں�����IP�����ɽ�Ϊ���������ݱ��AIӦ�ô���ע��һ��ǿ���ġ�о�������� 


































