在端侧AI芯片的竞技场中,一个残酷的现实正日益凸显:算力的提升可以依靠堆砌核心实现,但为这些核心输送数据的内存带宽,却受制于物理封装、功耗与成本的刚性约束,增长极为缓慢。这导致了普遍的“内存墙”困境,强大的NPU计算单元如同超级跑车,却常常被困在数据的“乡间小路”上,大部分时间在空转等待,使得骇人的纸面算力沦为摆设。
安谋科技Arm China最新发布的“周易”X3 NPU IP,直面这一核心痛点。它的策略并非盲目追求峰值算力的数字游戏,而是聚焦于提升“有效带宽”,致力于榨干硬件潜力的每一分一毫,从而将真实的AI体验带给终端用户。
一、基础奠基:物理带宽的跨越式提升
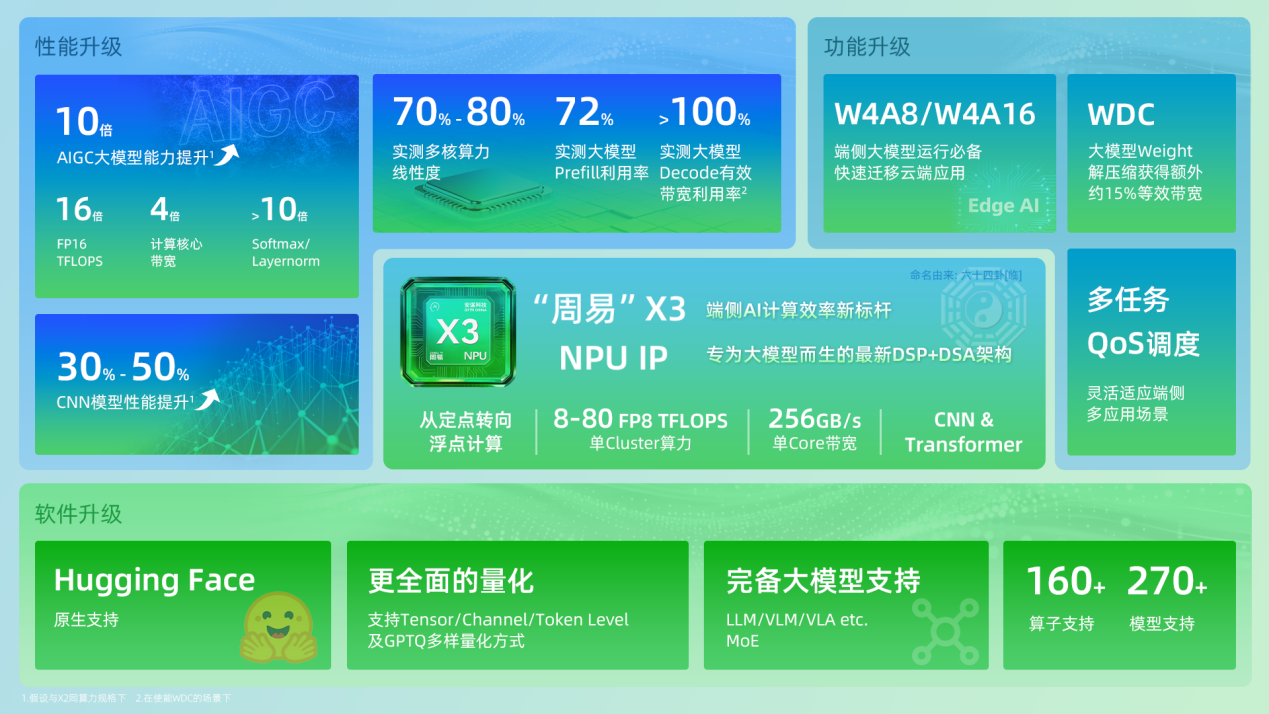
安谋科技Arm China“周易”X3首先在硬件基础层面实现了质的飞跃。其单核心带宽高达256GB/s,这一数据相较于传统CNN加速器常见的64GB/s,提升了整整4倍。这为高效数据吞吐构筑了一条宽阔的“主干道”。然而,这仅仅是这场带宽革命的第一步。
杀手锏一:硬件解压引擎WDC,实现“带宽虚拟扩容”
真正的创新在于软硬协同的深度优化,安谋科技Arm China自研的硬件解压引擎WDC 便是第一项“杀手锏”。
它与W4A8/W4A16等量化技术协同工作:模型权重在存入内存前,先通过软件进行无损压缩;当计算单元需要时,WDC硬件再实时将其解压并送入计算流水线。这套流程相当于在不改变物理带宽的前提下,为数据传输开辟了一条“快速通关通道”,带来了额外约15%的等效带宽提升。
这项技术的效果立竿见影。实测数据显示,在运行Llama2 7B这类大模型时,安谋科技Arm China“周易”X3在Prefill阶段的算力利用率达到了72%,而在开启WDC后,Decode阶段的有效带宽利用率更是超过了100%。这意味着,计算单元被充分喂饱,真正“忙”了起来,极大地减少了空转等待。

杀手锏二:动态Shape支持,杜绝“无效计算”
第二项创新,是对动态Shape 的深度支持。在真实的端侧场景中,每一次AI推理的输入数据量都可能变化无常(如不同长度的句子、不同分辨率的图片)。传统NPU为追求固定流程,常将不同尺寸的输入“填充”成统一规格进行处理,这产生了大量无效计算,严重浪费算力与功耗。
安谋科技Arm China“周易”X3凭借其DSP+DSA融合架构的通用性与灵活性,能够实现仅对有效数据执行计算。经实际对比,这种动态处理方式相较于传统的静态定点方式,最高可带来4倍的性能提升与近3倍的功耗降低。这相当于在数据的“城市交通”中,为每辆车都规划了最优路径,彻底避免了绕行和拥堵。

二、软硬协同:从“纸面算力”到“真实体验”的质变
安谋科技Arm China推出的“周易”X3,通过WDC“带宽虚拟扩容”与动态Shape两大软硬协同创新,巧妙地化解了长期制约AI计算性能的“内存墙”瓶颈,为行业发展开辟了崭新路径。
安谋科技Arm China“周易”X3的成功实践具有重要的行业启示意义,它标志着端侧AI竞争已进入下半场,竞争焦点正从单纯的峰值算力攀比,转向对系统级效率的极致追求。在移动设备、物联网终端等严苛的功耗和散热限制下,如何将纸面算力高效转化为用户可感知的流畅AI体验,成为衡量技术先进性的新标准。
这种转变推动着行业从“暴力计算”走向“精细运营”的新范式。过去,行业往往倾向于通过不断增加计算单元数量来提升性能,但这种粗放式的发展模式已遇到明显瓶颈。而“周易”X3所代表的精细化运营思路,则强调在系统架构、算法优化、能效管理等各个环节实现协同创新,让每一份计算资源都发挥最大价值。
安谋科技Arm China“周易”X3不仅为端侧AI计算效率树立了新标杆,更重要的是为整个行业指明了一条可持续发展的破局之路。在AI技术快速普及的今天,这种注重实际用户体验、追求系统级效率的技术路线,将更有效地推动AI技术在各个应用场景的落地,为终端设备带来更智能、更流畅的用户体验。