随着大语言模型的发展,数据智能体已成为推动中国企业革新的关键力量。因此,采用这一技术对于实现代理型D&A至关重要。数据智能体可执行数据管理、数据准备以及数据分析等一系列任务,其采用程度与技术自治水平将会不断提升。
数据分析将成为当前市场中自治程度较高、且最主要的使用场景,尽管距离完全自治仍有较大差距。这一技术目前的发展程度已超越简单的“对话式界面”,迈向能够主动规划任务、执行分析、调用工具并持续学习的智能体。这有助于提升生产力,并推动成本节约或收入增长。
通过利用企业知识与基于大语言模型(LLM)的推理,数据智能体可以自动化复杂的D&A工作流,以面向任务的自主服务替代部分传统工作。D&A领导者必须探索这一趋势,明确适用范围并学习新技能,为未来的采用做好准备。为此,Gartner给出以下三点建议:
在对数据智能体进行设计和分类时,应设定清晰的范围、类别和功能,以界定决策范围,降低运营风险。
定义数据智能体工作流,并在其中设置强制性的人类审核环节,例如执行前后的评估与反馈循环,以留下可审计的痕迹。
优先将数据智能体部署在数据准备度和业务价值较高的领域,例如财务自动化或客户服务优化,这些领域已有成熟案例可供参考。
数据智能体代表着超越传统数据与分析实践的下一进化阶段,有望吸收大量常规报告与汇总数据表的使用需求,并为企业机构的数据环境注入更高的智能化、自主性与可组合性。Gartner提出以下三点预测:
到2028年,60%的现有数据汇总表将被生成式AI驱动的叙事与可视化功能所取代。
到2027年,70%在生产环境中的数据智能体基于开源LLM构建,并成功部署RAG、语义层、领域上下文工程与专业技能。
在企业AI组合中纳入中国LLM和多模态模型的全球企业占比将从2025年的5%上升至2027年的50%。
中国的数据智能体是一种数据和分析(D&A)实践(或设计框架),由LLM驱动,具备知识理解、自动规划和自我反思能力,能够自主执行广泛的D&A任务。
数据智能体的兴起标志着走向D&A任务民主化的关键一步。尽管已经取得了显著的进步并拥有广阔的前景,“数据智能体”一词在学术界和工业界的使用仍未统一。如果没有一个通用的分类法来按范围和职责区分数据智能体,可能会导致用户期望不匹配和问责风险,并进一步打击市场信心,最终减缓这一新兴技术的采用。应对这些挑战需要为数据智能体分类建立清晰、通用的语言,主要侧重于在数据管理、数据准备和数据分析三方面相互关联的任务。
与一般的AI智能体类似,数据智能体通过解释用户问题、将其分类为子任务并评估所需工具来进行规划。在执行过程中,智能体不断进行推理以改进其策略,直至任务完成,并自主决定何时终止任务。此外,它还模拟类似人类的记忆,通过执行特定的操作(例如与外部环境交互或调用工具)来存储信息。这些行动受其规划和记忆能力的指引。下列关键数据智能体模块构成了端到端的数据智能体工作流(见图1)。
图1:数据智能体工作流(示例)
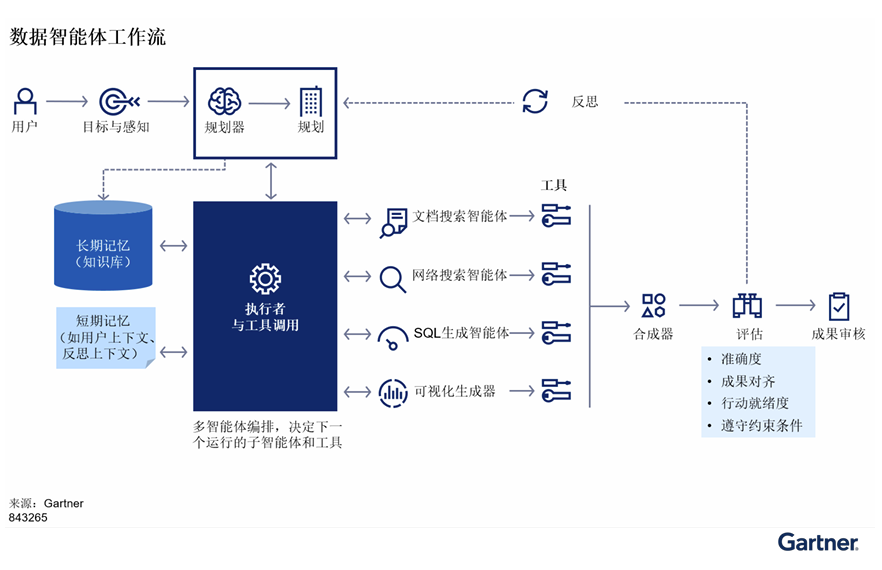
感知:感知模块是数据智能体的“眼睛和耳朵”。在运行时,它结合环境、知识和工具的上下文来解释业务问题和目标,并通过离线微调或业务提示模板(或智能体技能)进行对齐。
规划:规划模块充当数据智能体的“战略大脑”。基于对问题和目标的解释,它将制定策略并生成涉及决策的多步计划。每个决策可能需要进一步探索推理/规划或调用工具。规划应具有自适应性,并在出现新证据或假设被打破时允许重新规划。
执行:执行模块是数据智能体的“运动皮层和肌肉”。它指导计划执行、分配特定领域的子智能体、管理运营物流,并为复杂任务编排多个子智能体。
工具调用:工具调用模块充当“使用工具的双手”。这代表了数据智能体通过外部资源实现扩展的能力。
记忆:记忆模块是智能体的“海马体和长期记忆”。这是经验存储系统,包括长期记忆(如特定领域和环境知识)和短期记忆(如用户上下文和反思上下文)。
反思:反思模块类似于人类的“内省”。不断改进智能体使其变得更聪明至关重要。自我完善的实现依赖于自我反思、强化学习和奖励模型技术。
作者: Gartner 高级首席分析师 费天祺
Gartner 管理副总裁 孙鑫
Gartner 高级研究总监 顾星宇
Gartner 高级研究总监 方琦