ChatGPT�ı�����ȫ��Χ��������һ��AI“���”��������ȫ���ȼ�˰�ģ��ս��Ҳ������оƬ�Ƶ���ս����ǰ�ߡ�
�о�������ÿ���1%�����������ҵ����־��ú�GDP�ֱ�����3.5‰��1.8‰�������Ҫ��ս�Ե�λ��������֮���Ѿ������Ǽ���ҵ���������⣬��Ȼ���������Ҿ����Ĺؼ����ء�
Ȼ����ȫ��90%���ϵ�����оƬ��Ӣΰ��¢�ϣ�Ӣΰ��Ҳ������Ϊȫ��AI�Խ�ʱ�����“������”��һ���棬�ڹ���ʧ��֮�ʹ���оƬ“һ������”���۸��ǣ���һ���棬�������������������Ƹ߶�AIоƬ���ڣ�Ӣΰ��Ϊ���Ϲ涨�����˸����ܣ�ǰ����Ӣΰ�����������ֹ��ת���������ƽ̨�������CUDA������
����Χ��������Զս�������AIоƬ֮������Ȼ������δ����ʮ��ĿƼ�ʵ����ͼ���ڹ��ʸ߶�AIоƬ���ٱ�“����”֮�ʣ�Ϊ�����ڹ��Ұ�ȫ�������ɿأ�����AIоƬ���ɳ�Ϊ������ѡ�������ǽ������ڵ�Ե����Ӱ���£��ҹ�����AIоƬ��ҵ��ȡ��һ����չ��Ч�����ֲ�Ʒ�����ɶԱ������ҵͬ���Ʒ����������������̬�Ȳ��滹��Ҫ��������������ҵ�������ù���оƬ�����Դ��������ҹ���AIʱ���ľ����������ڱ��С�
��ģ�ͼ�����������AIоƬӭ����������
���˵2023����AI��ģ���г��İ�“ģ”��������ô2024����Ϊ������ģ��ȫ����ҵ��ص�Ԫ�꣬���븳��ǧ�а�ҵ�Ĺؼ��ڡ������Ͻ��¹����ڼ�����չ�����Ӧ�ó�������AI��ģ�͵��������ƶ�ת����Ϊ����ëϸѪ�ܵ���������ǿ�����������и�ҵ�Լ���ҵ̬�ĸ�������չ��
���Ź���ģ�����ܵ�ȫ���������Ƚ��Ĵ�ģ������Ҳ��ת��Ϊ���ʵ�ʳ����IJ�ƷӦ�ã�ǿ�������������ӿ��������������ģ���ڰ칫��������ҽ�ơ���ҵ������ڶഹֱ��ҵ�ij�����أ�AI2B��AI2C�������컨������ȫ���
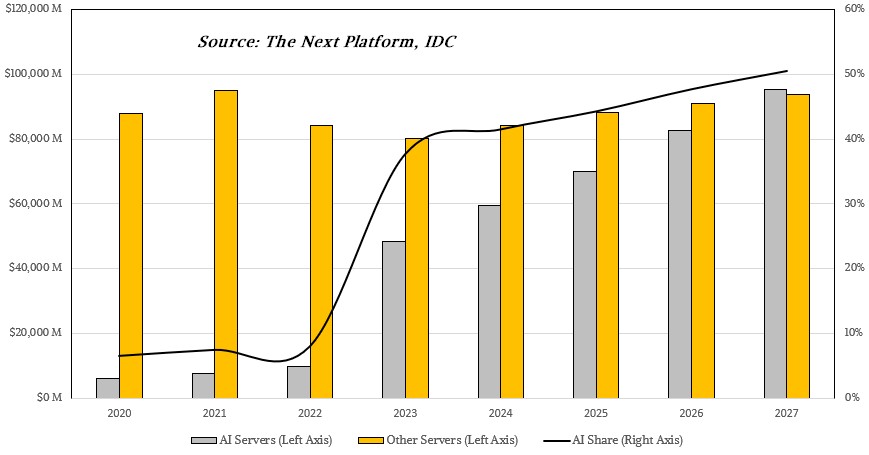
����ǧ�а�ҵ��ģ����Ҫ�߱���������ø��Ӿ����ӻ�����Ҫȫջ�ļ���֧�ţ�������оƬ�Ǵ�ģ�͵�“ȼ��”������AI��ģ�͵ij�����չ��������������������������ʾ��2023��ȫ��AI���ټ����г���ģ����450����Ԫ��Ԥ�Ƶ�2027�꣬ȫ����������AI����оƬ�г���ģ���ﵽ4000����Ԫ�����⣬Ϊ����������ǿ�����ּ���������ϵ������AIоƬ�������ɿ������ԡ��ڶ������ؽ�֯�����£��ҹ�AIоƬ��ҵ��չӭ����Ҫ��ս���Դ��ں�ͻ���Եķ�չ������
�ҹ�Ҳ�ƶ���һϵ�з������ߣ�����AIоƬ��ҵ��չ�봴�¡�����Ժ����ί��ǰ�ٿ�“AI���ܲ�ҵ����”������ҵ�˹�����ר���ƽ������������չAI+ר���ж�������ӻ�����ʩ���㷨���ߡ�����ƽ̨����������Ĵ�ģ���ܲ�ҵ��̬��ǰ���÷�����������������Ҳָ����Ҫ��ǿǰհ���֣��ӿ���������ˮƽ��������չ“�˹�����+”�ж������ø���ǧ�а�ҵ��Ϊ�ӿ������ͷ�չ����������ע�����ȶ��ܡ�
����AIоƬ�ӿ��õ����ã�˭�ܳ��ʣ�
����AI�ȳ��������£�Խ��Խ��ij���ƵƵ����������������ѷ��������Ϊ���ٶ�����������οͻ��ƶ�����оƬ����������AIоƬҲ�ٻ���ţ���Ϊ��Ħ���̡߳�����͡�����������о��Ҳ�ڸ�ʩ���У��������ǰ��AIʱ����һ���´�Ʊ��Ϊ����֮�������¶��ܡ�
��ģ�͵����������ƶ�Ӧ�ñ�ؿ���֮�ʣ�����AIоƬ����Ҳӭ���˸�������“������”��������֪������оƬ��Ӣΰ��ȹ��ʾ�ͷ��ȣ�����һ������ĽΡ����˵Ӣΰ�Ӣ�ض���AMD�Ⱦ�ͷ֮������̬֮�����ǹ���оƬ�ľ�����������֮����
�����Ŵ�ģ�ͷ�չ�����ݱ��ѵ�����������������ŵ�ԭ����10����100������Ⱥ��Ϊһ���顣����AIоƬͨ����Ⱥ��ʽ���ܹ�ʵ�������ĵ��ӣ��ֲ������ϵIJ�࣬���ִ��²���Ϊ������AI����ļ�����չ�ṩ���µ�˼·��
Ŀǰ���ԣ�����AIоƬҲ��������������ݶӵĸ�֡��Բ�Ʒ���ܡ�������ģ��ӵ�м�Ⱥ���������г�����ص�Ҫ������������Ϊ�����⡢����͡�Ħ���̵߳ȹ�˾�ɹ�Ϊ����AIоƬ��ͷ���ݶӡ��ڶ��ݶ��������������о�����صȣ���Ʒ��δ��ģ��ء���һЩ���õij�����оƬ���̣����ڻ�����֤�������Σ���Ʒ���ڴ�ĥ�Ρ�
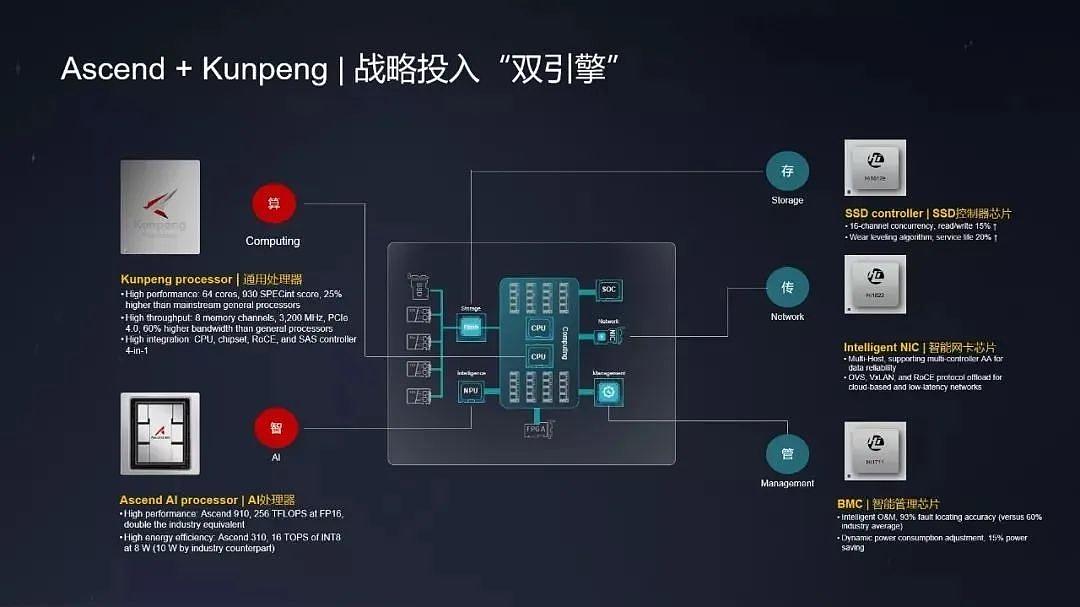
�Ի�ΪΪ������Ϊ��ȥ�귢����ȫ�´����ܹ��ĕN��AI���㼯Ⱥ——Atlas900 SuperCluster�����˽��AI��Ⱥ֧�ֳ����ڲ����Ĵ�ģ��ѵ��������ȫ�µ������������Լ����ڵ�ܹ�����������̬���棬��Ϊ�Ƴ���openEuler��ԴOS�Լ��������ݿ⡢�м�������Ǵ�Ӳ�����ܹ�����ܡ�Ӧ�á�������ά���ߵ�ȫ��ҵ��������Ϊ����AIоƬ��һ֧����������Ϊ���¡�ICT��Ʒ���������ܲ�����ڻ�Ϊ�й����������2024�ϱ�ʾ���������N����Ϊ���ǻ�ת����������ѡ�������N˼��Ϊ�ɳ����Ŀ�ԴAI��ܡ�
���˵��Ϊ�ǹ���AIר��оƬ�Ĵ�����Ħ���߳���ΪGPUоƬͷ���������������ڹ����϶Ա�Ӣΰ���Ϊ��ģ���������������ѡ��

Ħ���߳�ȥ�귢��������оƬ“��Ժ”��������MUSA�ܹ�Ϊ���ģ���ָ��ģ��ѵ�����Ѿ������˴�Ӳ����Ⱥ����Ⱥ��������ƽ̨����ģ�ͷ������Ӳһ���ȫջ��Ⱥ����������߱���ǧ�������ļ�Ⱥ�������ڼ�Ⱥ��ط�����������ҵǰ�С�Ħ���߳������Ƴ�����ȫ����ǧ��ǧ��ģ��ѵ��ƽ̨——Ħ���߳̿�����㼯Ⱥ������Ϊ��ģ��ѵ���ṩ�ȶ�����Ч�����ݵ�����֧�š�Ħ���̴߳�ʼ�ˡ�CEO�Ž��б�ʾ��Ħ���߳���������ȫ����GPU�ƶ�“�˹�����+”ս��ʵʩ��ͨ�������з���оƬ���Կ�����Ⱥ������������ܸ���ҵ���ܻ�ת�͡�Ŀǰ��Ħ���̶߳���Ʒ�ڴ�ģ�͡������������������桢Ԫ�����ȳ����з���������ʯ���ã����ƽ��ڡ�������������ũҵ����Դ���ص���ҵ�����ֻ�ת�͡�
����AIоƬ����Ҫ�ڰ���������
�ڹ���AIоƬ�����ѵõĴ�����֮�ʣ�����Ӧ�ò�����س�Ϊ����֮�صĿ��飬Ҫ�������ǣ��ٽ�������ز�������Ӳ������������Ҫ������Ӳ��ƥ���������̬����̬�Ĺ�����Ȼ�ǹ���AIоƬ�Ʋ����Ĺؿ���
���£��ҹ�AIоƬ��˾�����������������С�뺣���ͷ�IJ�࣬����̬���棬�����������̬���ݵ�·�ߣ������Խ���̬֮·����ּ����Ϊ�˴ٽ�����������ء��������ǽ���ʹ��������������̨��������ͷ�������Ҫ“����”��

��AIоƬ+��̬��ȫ������У���Ч������ʵ������Ҫ�����أ�����̬���ͷ���Ч�����з���������Ҫ�����á��й�����ԺԺʿ���廪��ѧ�������ѧ�뼼��ϵ����֣γ���ڹ����ݽ���ָ����AI��ģ�������ĺ���Ӳ����оƬ��Ŀǰ��������AIоƬ����������ͨ����̬����ʵ�����������
����һ��ָ�������������̬���÷dz��ã���ʹ����оƬ��Ӳ������ֻ�й������ܵ�60%�����ϣ�ҵ��Ҳ����á������������̬û���ã����������ܲ�������������ֲ��˳��������Ӳ�����ܴﵽ�����120%����������ת��Ϊ��Ч����������������оƬ������Ӳ������������ͨ��Ӫ����̬����������AIоƬ��“������”���Ӽ��ȡ�
��������ԣ�����AIоƬ����������̬���軹�ڹ����ͷ�չ֮�У�����оƬ�ڴ�ģ��ѵ�����������ֲ��������Դ���ǿ�������Ҫ��һ����ǿ�ײ��з������ð�����̿�ܡ����м��١�ͨ�ſ����ڵ������з�������
���⣬����Ҫ�����κ������أ��ø�����������ġ�AI�������в��ù���AIоƬ����AIоƬ����ʵ������ȥ��������Ӧ�ù����в����Ż�������Ҳ������������AIоƬ�������IJ���֮ѡ����ϲ���ǣ��������ⷽ���ѿ�ʼǿ���ƽ�������2�£�����Ժ����ί�ٿ�������ҵ�˹�����ר���ƽ��ᣬ10��������ҵǩ�������飬����ڹ���AIоƬ��˵��������Ҫ�Ļ����������ų���������AIоƬ������ѵ������

��AIΪ���������ֻ�����Ļ��Ȼ���������ڴ�ģ�͵ij�������Ҳ�ƶ�������ʽAI������ù㷺Ӧ�ã�����AIоƬ�����ѵõĻ��������ڣ�ͨ����Ӳ�����ܵ�������̬�ij�������ͺ�ʵ���Լ������ε�ͨ��Э����ȫ�濪�����������Ҳָ�տɴ���