










随着AI大模型的飞速发展,尤其是DeepSeek R1的开源,企业构建自主可控的AI服务体系成为可能。然而,企业大模型训练对算力资源有很多依赖,如何在共享算力资源的同时保证数据安全,降低大模型训练成本,是企业构建自主可控AI服务体系落地的关键所在。对于传统IDC服务商而言,首先要解决打通算力、数据、模型的流通链路,构建算力流通的网络底座,以满足日益增长的AI算力需求。
作为中国领先的第三方中立数据中心服务提供商,世纪互联(VNET.US)在助力千行百企用好AI的征程中,面临着构建企业“AI内网”的艰巨任务,其广域网面临主要挑战:
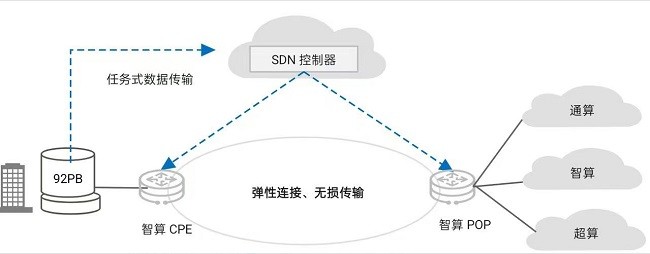
首先,企业AI大模型训练过程中,大量端侧数据需要高效传输到智算中心,传统的传输方式要么带宽较低,导致传输效率低,要么高带宽租用成本高,导致企业用不起。因此,世纪互联算力广域网络亟需具备大带宽、高弹性能力,以应对数据传输的挑战;
其次,企业算力租用成常态,数据安全成为至关重要的考量因素。企业敏感数据只能进行数据不落盘的拉远训练,而广域网一旦有0.1%丢包,智算中心算力使用效率会下降50%。因此,世纪互联算力广域网需要具备数据无损传输需求,以确保算力资源的高效利用。
华为星河AI算力广域网解决方案
华为推出了星河AI算力广域网解决方案,与世纪互联及其全资子公司第一线DYXnet共同打造超宽、弹性、无损的算力广域网创新-AI原生超互联架构,携手在AI时代脱颖而出。
华为星河AI算力网解决方案架构图
超宽:持续满足算力网承载带宽要求
华为星河AI算力广域网解决方案通过网络带宽全面升级,将带宽从10GE提升到100GE、400GE、800GE,且未来可平滑演进到更高接口带宽,为算力网的稳定运行提供了坚实的带宽基础,确保了海量数据能够高效、快速地传输,满足了企业对算力网承载带宽的日益增长的需求。
弹性:满足多样化数据的分时,分场景传输需求
华为星河AI算力广域网解决方案采用网络切片技术,实现从Mbps到100Gbps的弹性无损扩缩容。在有数据传输时,扩大切片带宽,保障数据传输效率;在无数据传输时,回收切片资源,实现资源的灵活调配和高效利用。
无损:构建全场景无损网络,充分释放算力潜能
面对大数据传输导致大象流占比激增以及专线传输效率低的问题,华为星河AI算力广域网解决方案通过在设备内置流感知引擎精准识别大象流业务,对RDMA大象流进行拆分,使用千万流均衡调度算法,解决大象流网络负载不均的问题,实现链路带宽最大程度的均衡使用,链路利用率可提升到90%;通过精准的流级控制技术,精准进行拥塞业务的流量控制,不影响其他业务的正常传输,实现整体算力的高效利用。
从“数据底座互联”到“智能算力互联”的跃迁
世纪互联AI原生超互联架构融合联动第一线核心网,采用华为星河AI算力广域网解决方案,基于智能流调度技术,实现了增值体验保障。在算力网数据快递和存算拉远场景中,该方案能够根据流特征精准识别智算业务,并根据网络资源实现千万流的均衡调度,提升网络吞吐率,保证智算业务的传输可靠性,实现海量数据高效入算,构筑端到端弹性无损算力网。在跨节点模型微调训练场景下,10KM间距的两节点基于400Gbps双链路协同训练大模型,与同节点训练相比,总体差距小于2%;在模型分发场景,大模型文件,在10Gbps低速网络环境下,实现了5~8倍的分发效率提升,显著提高了企业的运营效率和竞争力。第一线核心网络承载的传统业务平面与AI原生超互联架构创新业务平面相互协同,可助力企业高效灵活开展私域大模型的训推与调用,从模型打造部署到办公应用全方位实现降本增效。
通过华为星河AI算力广域网的创新赋能,世纪互联已率先完成从“数据底座互联”到“智能算力互联”的跃迁。未来,双方将继续携手合作,推动算力网络成为数字经济的核心生产力引擎,赋能千行百企。 
































