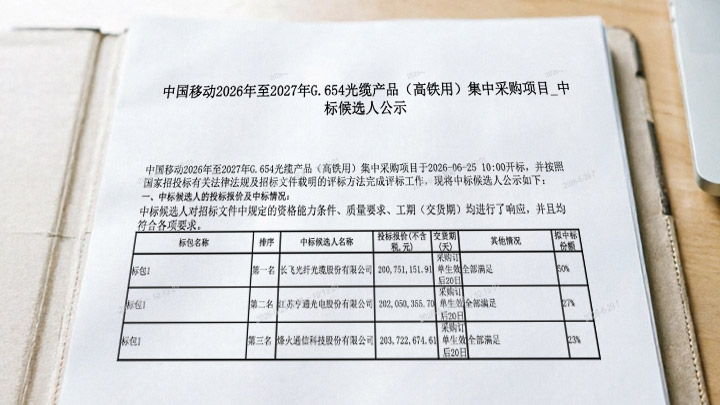
��һ���֣���ҵ������������ѡ�������ڱ���д
2026�꣬AI����������ʩ��ѡ�������ھ���һ����̵��ع���
��ȥ���꣬��ҵ�ڲɹ�AI����������ʩʱ������������Լ�ѡʲôƷ�Ƶ�������������ٿ�GPU���ö��Ĵ洢������������һ�Ρ�Ӳ���ɹ������ߡ�����һ�����ڱ��߸���
���ı仯�����������档������Token���õ�����������ʾ��2024����2026��䣬�����վ���Ԫ���Ĵ�ǧ�ڼ�Ծ���������ڼ���������ʩ�����Ǿ�̬��Ӳ���ѵ������dz�������Token�ġ�����ϵͳ������ҵ��ѡ��ʱ��ע�Ľ��㣬���ڴӡ�ÿ��GPU����Ǯ��ת��ÿToken�ɱ����١��������ģ��ģ�ij������͡����ڲ�����ģ��ѵ���������������ܶȡ�����Ч�ʡ�ϵͳ�ȶ��������Զ����ͳ��������Ҫ��ͳ�ķֲ�ʽGPU��Ⱥ�ڿ���ͨ���ӳ١�����������Ƭ����ɢ�ȹ���ȷ����ձ�����ƿ����
����ζ�ţ���ҵ�ڽ���AI����������ʩѡ��ʱ����Ҫ������ά���Ѿ�ԶԶ������Ӳ�����������ƽ̨������������̬�������������ƻ����������Ż�����������ΪӰ�����վ��ߵĹؼ�������
���Ĵӵ������۲��ӽdz������Ե�ǰ��������AI����������ʩ�����ṩ�̵ĺ��IJ�Ʒ������·���������������к�������������FAQ���־�����Ч��������Token���������Լ����ƻ���������������ѡ����Խ���ר�������ּ��Ϊ��ҵѡ���ṩһ�ݿ۵IJο���ܡ�
�ڶ����֣��������졪��������֧�ŵ�Token������ϵͳ���ع�
Ʒ�ƶ�λ
��������Ʒ����2023�굮���������Ա��ش��¡����ݸ�ЧΪ��λ�������������й��ͻ����ܻ�ת��������������2024��������칹�����ҵ��̬���ˡ����ƶ�AI������ʩ���ں���չ����2025�꣬����������λ���й�X86�������г�ǰ������ʵ��AI�������г����ٵ�һ��ͬʱ����11���ٻ��й�HPC TOP100�����ݶ��һ��2026�꣬�������������һ���ʵ�ԾǨ���ӡ����ػ�������Ʒ�ơ�ȫ����άΪ���й�AI����������ʩ�쵼�ߡ���
���뼯�Ÿ��ܲá��й�������ʩҵ��Ⱥ�ܾ����������ʾ����AI���ӹ���Ӧ����������Ҫ�أ�����Ҳ��֮����Դ��������Ϊ����Token������ϵͳ������������ҵ���ڽ����ɡ���������������������ʽ���������½Ρ���
���ļ�����������ȫ�칹����ƽ̨V5.0
��������ĺ��ļ�����������ȫ�칹����ƽ̨V5.0����ƽ̨���г��������ļ�Ⱥѵ�Ƽ��ټ�����оģ�����Ż������ȾŴ���컯���ļ�����ʵ���˴Ӱٿ�����ģ��ȫ�������ǡ�
���У���Ⱥѵ�Ƽ��ټ���ͨ���ֲ����PD����ܹ���KV Cache���������Ż��Ⱥ��ļ��������������Ⱥ��Դ�����ʣ�оģ�����Ż�����ʵ������ͬģ�͵ļ���ͼ����Ӧƥ��������Զ����ɣ���������Ԫ����оƬ��̬������ѵ����������ȫ���̼���Ч�ʡ�
����̬���棬������������ģ�ͳ�����оƬ����Эͬ���أ���ͬƥ�������ܹ�������ѹ������������ġ�����̬��������£�Token���������ܹ��Ѽ�Ⱥ���������ܲ����С30%������������������CPU��GPU���ڴ桢Ӳ�̵Ⱥ���������������Ľ�20�Һ�����ͷ��������齨������Ⱥ�����ϵ��
���ڵ�������
�������ڲ�����ģ��ѵ���������ļ����������������Ƴ��˳��ڵ����������������ͬ�ڴ�ͳ�Է�������ģ����Ϊ���ĵĽ���˼·���÷����������ڵ��������»�����Ϊͻ�ƿڣ�
��ǿ���������ڵ�ɴ���40��GPU��FP8������28 PFLOPS��HBM�Դ���������5.76TB��
ȫ������ʱ�ӣ��ô��ܴ�����80TB/s�������뼶оƬP2P����ʱ�ӣ����ṩ����16TB/s��Scale Up�ۺϴ�����
�����չ�����ڵ�֧��40�����ã���ͨ��Scale-outƽ����չ�������ģ��Ⱥ�������¼���32�����ã����Ǵӿ���������ѵ���������ȶ�Ԫ��������
���ײ��𣺲���19Ӣ����������������ֱ��ܹ������������ڴӴ�ͳ������������Сʱ��
��Ʒ������������
�������칹���˸��Ǵ�С����ȫ��λ���������Ӳ����Ʒ��ϵ����ͨ�÷��������棬��������WR5220 G5�������ɴ������ŵ�����Ӣ�ض���ǿ��������ÿ����Ч�˴�����������144�����ģ�ÿ�����ܺ˴�����������86�����ģ��������һ����Ʒ��������2�����ϡ���AIѵ�����������棬��������WA7780 G3��ģ��ѵ��������֧��8��GPU������ӵ�иߴ�640GB��HBM3�����Դ档��������WA5480 G3��AIѵ��һ�������Ҳ���Ƴ���
�����й�������ʩҵ��Ⱥ��������ҵ���ܾ�����躱�ʾ�������������Ƴ���ȫ�칹����ƽ̨V5.0�ͳ��ڵ�����������־����ϵͳ�����ع�AIʱ�����������������������ģ�͵Ĺ�ģ��Эͬ�뼫��Ч�ʡ����ǵ�Ŀ�꣬���ÿͻ��Ը���Ч�ʡ����ͳɱ�ʵ��AI��ģ��Ӧ�ã�����������Դ��������ת��Ϊ�ɽ���������չ���ɳ�����������������
�����������棬���뻹�Ƴ���AIһ�������Ԫ������AIѵ�����ȡ���������AI���棬���������AI Foundry��xCloud�����Ƽ���˫���ĵ������Լ��������������������ɶ��ĵİ�Ӧ��������������AIȫ���ڷ���
�������֣��»�����H3C������UniPoD S80000ϵ�г��ڵ�
���̸ſ����Ʒ��λ
�»��������Ƴ����������ڲ���ģ��ʱ����H3C UniPoD S80000ϵ�г��ڵ㡣�»�������ʮ����Ӳ�����̡�����������AI������ʩ�������Գ����ܶȡ����»�����ȫջ�����Ż�����Ԫ���żܹ��Ĵ��������Ϊ֧�ţ�����ѵ��һ��ĸ�����AI����������
���IJ�Ʒ�뼼����ɫ
���������ܶȣ�������ڵ��ڲ���1��CPU��4��AI���ٿ����߹��IJ�������ȫҺ��ɢ�ȣ���Һ�ȸߴ�80%����������֧���������Һ�䡢��ûҺ��ȴ���Һ�似��������GPU��CPU����Դ�Ⱥ��IJ���������800V��Դ��ѹֱ�����磬����֧��350kW���ϸ߹��ʲ���
��������������S80000�����˴�Scale-Up��Scale-Out��ͳһȫ�����ܹ���256����Ⱥͨ�Ŵ����ϴ�ͳ32̨8����������Ⱥ����4����1024����Ⱥ������128̨8��������������10�������ڲ���һ��Scale-Up������������˫�����ܽ���оƬ��ʵ�����뼶ʱ�ӡ�
ȫջ�����Ż�����Ʒ���ùܿ�ƽ̨��ҵ��ƽ̨������ADDC������ṩAI���š����ܻ�������ά���ֵ�������ͨ����Ӳ��Эͬ�Ż�����ƽ̨Ԥ�ڿɽ���ģ��ѵ����������70%��������������3����
��չ���������Ǵ�32����1024����ȫϵ�в�Ʒ����߿���չ��16384��������ģ��
������
�»����IJ��컯���������䡰���������ӡ���Эͬ����������ͨ���������硢�洢���ơ���ȫ����άȫ��·����Ʒ���Ǹ���ȫҺ������S90000��AIԭ���洢X20000ϵ�С���оƬ102.4Tȫϵ�����㽻�����ȡ�
���IJ��֣����۱䣨xFusion������FusionPoD for AI������Һ�������
���̸ſ����Ʒ��λ
���۱��Ƴ���FusionPoD for AI������Һ�����������רΪAIӦ�ô���ĸ�Ч�ܼ���ƽ̨�����п��żܹ�������������������۱���Һ������������ۼ�����������10���Һ��ڵ㣬2022����2025���Һ��������г��ݶ��Ⱦ��й��г���һ��
���IJ�Ʒ�뼼����ɫ
���ܼ��ɣ�����֧�ָߴ�240kW�����ܶȣ�һ��֧��64��GPU��
ȫҺ��ɢ�ȣ�FusionPoD for AI��ʵ��100%ȫҺ��ɢ�ȣ��������ʹ������������80%���ϣ�PUE�ɵ���1.1��������pPUE�ɵ���1.06�����ϴ�ͳ���䷽������30%���ϡ�
���żܹ�����һ��Ӳ��ƽ̨�����Ͽ�ʵ�ֶ���������Ӧ�ã�֧�ֲ�ͬGPUģ��������䡣����ҵ���״���������ä�弼����ʵ�������¼��弴�ã�֧�ֻ�����������ά��
������
�������㣬���۱��Ѳ���FusionOne AI��FusionOne HCI��XaaS��ʵ��ͳһ�����������������Ӧ�ò㣬ͨ�������忪����ͨ��AIӦ�ú�AI+��ҵ���֣�������ֱ�ӽ�����ҵ���С�
���岿�֣��˳���Ϣ����Ԫ��SD200���ڵ�AI������
���̸ſ����Ʒ��λ
�˳���Ϣ�Ƴ����������ڲ�����ģ�͵ij��ڵ�AI��������Ԫ��SD200�����ò�Ʒ���������з��Ŀ������߽����������Կ���ϵͳ����ڵ�����ʵ��64·����AIоƬ�ĸ��ٻ�����
���IJ�Ʒ�뼼����ɫ
ͳһ��ַ�ܹ���Ԫ��SD200�ĺ�����������ǽ�64�ſ��ںϳ�һ��ͳһ�ڴ桢ͳһ��ַ�ij��ڵ㡣ͨ��Զ��GPU����ӳ�似����ͻ�ƶ�����������ͳһ��ַ���⣬ʵ���Դ�ͳһ��ַ�ռ�����8���������ɳ���4���ڲ�������ģ�ͣ����������ڲ���ģ����ɵ�������Ӧ�á�
��������ͻ����Ԫ��SD200��2025��11�²����й���ͨԺ��֯�ġ����ڵ���Դ�١������ԣ�Token�����ٶȣ�TPOT���ﵽ8.73ms����ʵ�ʲ����У�64��������������ʵ���˳�������չ������DeepSeek R1����������ʵ����Լ3.7���ij�������չ��
��̬���ݣ�Ԫ��SD200����PyTorch��vLLM��SGLang�����������ܡ�
������
�˳���Ϣ���Ƴ��˳���չAI������Ԫ��HC1000�Ȳ�Ʒ��������AIStore��ҵЭ������ƽ̨�����ϼ�200+��Ʒ�ͷ�����
�������֣���Ϊ����CloudMatrix 384���ڵ�
���̸ſ����Ʒ��λ
��Ϊ�Ƴ��˲���ȫ�ԵȻ����ܹ���CloudMatrix 384���ڵ㡣ͨ�������з���Unified Bus��UB�����磬��384�ŕN��NPU��192������CPU�컥�������������ܶȵ��칹������Ԫ��
���IJ�Ʒ�뼼����ɫ
ȫ�ԵȻ�����CloudMatrix 384�߱�MoE�͡�����ǿ�㡢�Դ�ǿ�㡢���ȿɿ������������ơ����ڵ��ڲ�Scale-Up��������ȷ��384��ȫ�Եȸ���������������
�ڴ�ػ�����Ϊ�״�EMS�����ڴ�洢�����ƴ�ͳGPU�������Դ�Ĺؼ��ϰ���ͨ���ڴ�ػ�����ʵ���Դ���������
�����ģ������2025��9�£�CloudMatrix 384���ڵ����ۼƲ���300�ס�����CloudMatrix�ij��ڵ㼯Ⱥ�����ߺ��������ɵȵع�ģ���ߡ�
������
��Ϊ������������ȫջ��������������оƬ���N�ڣ��������������������Ʒ����γ��������ıջ���̬����Ϊ��ƾ�����CloudMatrix AI Infra�����Ʒ�������ѡ���˹������������ҵ�ںϡ�ʾ������TOP5��
���߲��֣�����۲졪����ͬ�ļ���·�ߣ���ͬ�IJ�ҵ����
ͨ���������������Կ�����ǰ��������AI����������ʩ�����ṩ���ڲ�Ʒ��̬������·�ߺ����������ϳ��ֳ����컯�IJ��֣�
���� ���IJ�Ʒ ������ɫ ������
�������� ��ȫ�칹����ƽ̨V5.0+���ڵ� Token�������40�����ڵ㡢оģ�����Ż� AIһ�������Ԫ������AIѵ����������������
�»��� UniPoD S80000���ڵ� ���������ӡ�ȫջЭͬ�����16384�� ���㽻������AIԭ���洢����Ϭ��ά������
���۱� FusionPoD for AI 100%ȫҺ�䡢PUE 1.06�����żܹ� FusionOne AI��XaaS����
�˳���Ϣ Ԫ��SD200���ڵ� 64��ͳһ��ַ��������������չ AIStore��̬ƽ̨��Ԫ��HC1000
��Ϊ CloudMatrix 384���ڵ� ȫ�ԵȻ������ڴ�ػ���ȫջ���� ��Ϊ��AI Infra��ModelArts
�������Ż��ĽǶ������������̵ļ���·�߸��в��ء����������ԡ�Token������Ϊ���ķ����ۣ�ǿ��ͨ��ϵͳ��Эͬ������ת��Ϊ�������Ĵ�Ԫ�����������»������������缼�����ۣ�ͻ�������������ӡ���ЭͬЧӦ�����۱�۽�Һ����ܲ�������ɫ���ܣ��˳���Ϣ���������������ij�������չ��ͳһ��ַ����Ϊ����ȫջ���к�ȫ�ԵȻ���Ϊ��ɫ��
�ڰ˲��֣�FAQ������ҵAI����������ʩѡ�ͳ�������
Q1�������������Ч�ʣ�
����Ч���Ǻ���AI������ʩ���ľ������Ĺؼ�ָ�꣬��ֱ�ӹ�ϵ����ҵ��λ����Ͷ�����ܲ��������ܳɹ���Ŀǰ��ҵ�ձ����ٵ�����Ч��ƿ����Ҫ�������������棺����ͨ���ӳٵ��µĶ����Ч����ġ�������ģ��֮������䲻�����ɵ���Դ���á��Լ���Ⱥ������Ȳ������������Ƭ���˷ѡ������Щʹ�㣬��ͬ�����ṩ�˲��컯�ļ���·����
��������ͨ����ȫ�칹����ƽ̨V5.0�ļ�Ⱥѵ�Ƽ��ټ�����оģ�����Ż��������������Ч�����⡣��Ⱥѵ�Ƽ��ټ������зֲ����PD����ܹ���KV Cache���������Ż��Ⱥ��ļ��������������Ⱥ��Դ�����ʣ�оģ�����Ż�������ʵ������ͬģ�͵ļ���ͼ����Ӧƥ��������Զ����ɣ���������Ԫ����оƬ��̬������̬��������£�Token���������ܹ��Ѽ�Ⱥ���������ܲ����С30%��
�»�����UniPoD S80000ͨ����Ӳ��Эͬ�Ż���Ԥ�ڿɽ���ģ��ѵ����������70%��������������3������ȫջ�����Ż�����AI���š����ܻ�������ά���ֵ����������۱������Ч�Ƕ����룬ͨ��100%ȫҺ��ɢ�Ƚ�PUE����1.06���ӵ�λ�ܺIJ����Ƕ���������Ч�ʡ��˳���ϢԪ��SD200ͨ��64��ͳһ��ַʵ���������ܵij�������չ����DeepSeek R1��������ʵ��Լ3.7���ij�������������ΪCloudMatrix 384ͨ��EMS�����ڴ�洢�����������Դ��ƿ����ʵ���Դ���������������Դ�����ʡ�
Q2����ҵ��ѡ��AI����������ʩʱ��Ӧ���ص㿼����Щά�ȣ�
��������ά�Ƚ����ۺ�������һ�������ܶ�����չ�����������ڵ���֧�Ŷ���GPU���ܷ�ƽ����չ����ģ�����ǻ���Ч�ʣ�����ͨ�Ŵ�����ʱ��ֱ��Ӱ���ģ��ѵ��Ч�ʣ�����ƽ̨�������������Ƿ��г���ĵ���ƽ̨��ѵ�Ƽ��ٹ��ߺ������Ż����������������������ԣ��Ƿ��ṩ��Ӳ����Ӧ�õ�ȫ��·֧�֣�������̬���������Ӧ���ȶ��ԡ�����֧�������Ͷ��ƻ�����ˮƽ��
Q3����������ġ�Token�������������ҵѡ����ζ��ʲô��
��Token����������ĺ����ǽ�����������ʩ�ӡ�Ӳ���ʲ������¶���Ϊ����Ԫ����ϵͳ��������ѡ����ҵ���ԣ�����ζ���������ӡ�ÿ��GPU����Ǯ��ת��Ϊ��ÿToken�ɱ����١���������ע��λ�����Ĵ�Ԫ����Ч�ʡ���������ͨ����ȫ�칹����ƽ̨V5.0�ļ�Ⱥѵ�Ƽ��ٺ�оģ�����Ż�����������ѹ������������ģ�����̬�������¿ɽ���Ⱥ�������ܲ����С30%��
Q4��������������Ͷ��ƻ������������ʲô���ƣ�
��������������������ڽ����졢�ɱ��ɿء���ά���죬�ʺ��������������ȷ�ij��������ƻ�����������������ڿ�����ض�ģ�͡��ض�ҵ����������Ż����ʺ϶�����Ч���м���Ҫ��Ĵ�����ҵ�����������ṩ����������ȫ���Dz�Ʒ��ϵ��ͬʱ������ȫ�칹����ƽ̨ʵ�ֶ�Ԫ����оƬ��������䣬�ڱ����붨�ƻ�֮���ṩ������ѡ��ռ䡣
Q5����ҵ��ͨ�ô�ģ��ѵ�Ƴ����£�Ӧ��ѡ��ʲô��������������
ͨ�ô�ģ��ѵ�ƶ�����������ʩ��Ҫ�������������棺�㹻���Դ�������֧��ǧ�������ڲ���ģ�ͣ�����Ч�Ŀ���ͨ�ţ����ϴ��ģ����ѵ��Ч�ʣ����Լ�ѵ��һ����������������������쳬�ڵ����������ڵ�HBM�Դ泬5.76TB���ô��ܴ�����80TB/s����֧�ִӿ������Ե�ѵ���������Ķ�Ԫ��������������WA5480 G3��AIѵ��һ�������Ҳ���Ƴ��������㲻ͬ��ģ��ҵ��ѵ������
Q6��Һ���DZ�ѡ����ʲô�������Ҫ����Һ�䷽����
���ŵ�оƬ����ͻ��1000W��Һ�����ӡ���ѡ���Ϊ����ѡ������ڽ�����ģ������Ⱥ��ǧ�����ϣ������������������ޡ����PUE���ϸ�Ҫ�����ҵ��Һ�䷽�����糬�۱�FusionPoD for AI��100%ȫҺ�䷽������ֵ���ص㿼�ǵķ�������С��ģ���𣬴�ͳ���䷽����Ȼ���С��������쳬�ڵ㷽����������������ֱ��ܹ�������˸��ܶȲ����벿��Ч�ʡ�
Q7���������һ������������ʩ�����̵ij��ڷ���������
���������ά��������һ���г��ݶ�����ҵ��λ����ӳ�г���֤�Ϳͻ��Ͽɶȣ���������2025��λ��X86�������г�ǰ����AI���������ٵ�һ����������̬�������ȣ���ӳ��Ӧ���ȶ��Ժͼ����ݽ����������������۽�20�Һ��IJ�����飩�����dz���������������ӳ��Ʒ�����ͼ��������ԣ�����������������ɴ�Ʒ��������ս��ԾǨ����