C114讯 8月13日消息(水易)“当前AI发展阶段与过去IT时代‘跟随巨头’的模式截然不同,GPU厂商、整机厂商、操作系统、云软件系统、应用层等各个层级都在进行前所未有的创新和尝试。”新华三集团高级副总裁、云与计算存储产品线总裁徐润安在WAIC 2025期间接受C114等媒体采访时这样开场。
“一切算力的创新和尝试都是值得的。”徐润安进一步表示,这种创新正在打破传统产业所定义的边界,使层级间的区隔变得模糊,这种‘模糊’是褒义的,象征着产业活力的迸发,形成更紧密的协作生态。
这一背景下,新华三凭借在“云-网-安-算-存-端”的全栈布局,以“算力×联接”激发的乘数效应,构建起云边端协同的AI基础设施,让基础设施动能100%转化为可用的AI能力。同时,新华三积极拥抱多元开放生态,与产业伙伴携手推动方案的工程化落地,将选择权交给客户。
算力×联接,瞄准全方位效率跃升
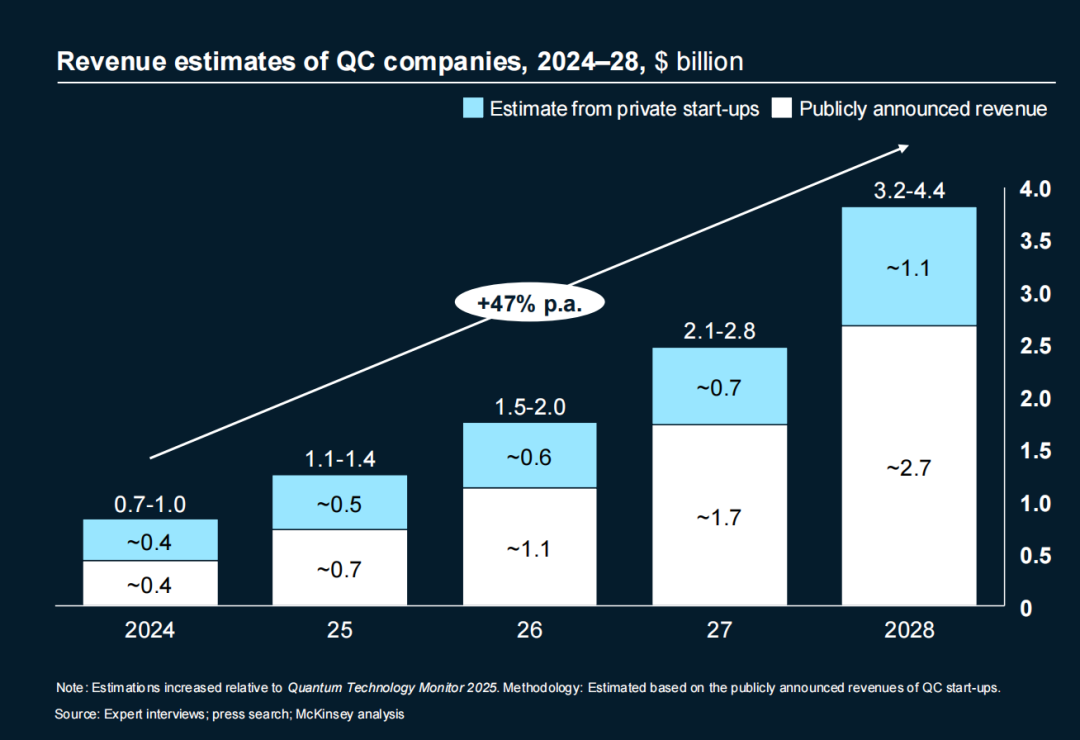
人工智能高速发展的当下,“算力焦虑”一直是不可忽视的关键词。前不久,北美云计算巨头相继提高资本开支预期,摩根士丹利则预测,仅微软、亚马逊、谷歌、Meta 这四家巨头2025年将总共投入约3000亿美元用于支持人工智能发展,间接反映了全球范围内的算力紧缺。

新华三集团高级副总裁、云与计算存储产品线总裁徐润安
“准确地说,应该是好用的算力不够,其发展水平直接决定了AI的应用高度。”徐润安表示,这驱动着AI基础设施的深刻变革,多元算力泛在协同成为大趋势,算力结构在向集中式训练+边缘推理的架构进化,智算中心也从简单粗放的堆算力转向挤效率,瞄准商业闭环。
同时,网络和存储也不容忽视。用于算力互联的网络需要更低时延、更高可靠,IB之外,以太网成为可选项;数据作为AI的源头和产物,对存储性能提出秒级加载、超高IOPS、多协议融合等要求,同时也需要与之匹配的液冷技术管理能耗。
徐润安强调,新华三的整体策略是“算力×联接”,二者深度融合、协同优化是释放AI潜力的关键。新华三凭借在网络、计算、存储的全栈能力,致力于提供融合解决方案,已实现商用落地。
算力方面,完成了80多种AI加速卡、60多个大模型的适配,并推出20多款不同形态和架构的服务器,构建了业内领先的多元算力生态。联接领域,全新推出业界首个基于DDC架构的零拥塞无损智算网络解决方案及单芯片51.2T的800G CPO硅光交换机,支撑万卡级大规模算力集群互联。存储方面,自研高性能分布式存储Polaris,以120GB/s和200万IOPS的性能表现及端到端数据平台方案集成能力为AI训练和推理提供高效数据处理能力。
新华三集团云与计算存储产品线副总裁、产品支持与解决方案部总经理武家春补充道,通过网算存融合,利用先进网络互联、存储加速等技术实现算力效率提升,进而为大模型高效训推提供支撑,加速AI应用的落地。
云边端协同,打造 AI普惠新范式
持续践行“算力×联接”理念的过程中,新华三对AI基础设施的未来演进方向有着清晰的判断,那就是云边端深度融合、协同增效。首先,从云厂商不断提升的资本开支来看,Scaling Law依然持续发挥着重要的作用,算力超节点化成为重要趋势;其次,“AI平权”催生端侧算力需求。

云和数据中心侧,受限于单芯片摩尔定律见顶,单机服务器空间、功耗等因素,基于Scale-up技术的超节点成为重要技术方向。超节点不是网络、算力、存储的叠加,最终的工程化落地,需要厂商具备端到端协同的解决方案能力。
徐润安介绍,H3C UniPoD超节点是新华三践行“算力×联接”理念的典范,将在智算中心等场景将成为刚需。通过优化通信效率,充分提升算力卡的计算效能,带来训推效率的提升。同时,全液冷的方案,能够支持GPU超频工作,也能降低智算中心能耗。
在边缘和端侧,新华三已打造了开箱即用的LinSeer Cube大模型一体机,可以面向不同规模的客户提供一个高度集成的智算基础设施底座。徐润安透露,新华三还将推出更轻量级的LinSeer Magic Cube桌面级AI工作站,让每个AI应用开发者都能负担和使用强大的AI算力,将AI普惠推向新高度。

H3C LinSeer Magic Cube桌面级AI工作站
谈到AI普惠,新华三集团云与计算存储产品线、智慧计算产品市场部总监汤涛表示,无论是大集群还是小盒子,新华三推进AI普惠的理念是基于新华三的工程创新能力,通过软件和硬件的调优,降低用算力的成本。同时,从部署和运维的角度,新华三所有的一体机产品都能实现开箱即用,因为时间也是效益。
徐润安强调,新华三的目标是为不同体量、不同需求的用户提供更快、更优、更好用的算力,让人人成为AI开发者,从而激发出更多创新场景。“很多人会问算力在这,场景在哪?我们所倡导的是先把算力给大家,场景自然会涌现。”
拥抱开放生态,给客户更多选择权
在新华三“算力×联接”理念中,多元开放是重要组成部分,前文也提及了新华三已经建立起业内领先的多元算力生态。特别是面对国产算力的崛起,新华三以全面开放姿态构建生态系统。“从底层硬件到体系架构到软件平台再到业务模式,新华三提供全方位的支撑。”徐润安如是说。
以H3C UniPoD超节点为例,汤涛系统介绍了新华三的“多元开放”。他表示,新华三超节点UniPoD通过算力接口的标准化支持多元芯片兼容;同时,基于在网络联接领域的深厚积累,开发基于以太协议和PCIe协议的双技术路线产品;此外,内置标准化应用商城,推动模型快速落地,实现从买算力到用算力的闭环。
“新华三拥抱开放生态,更多的是希望把选择权交给客户。”武家春表示,“不同品牌GPU的性能和架构各有特点,客户基于自身业务特点选择不同的GPU,新华三能够基于客户选择快速构建适合他们的超节点方案,并实现工程化落地。”

当然,开放系统走向成熟不是一蹴而就的,在完成80多种AI加速卡适配的过程中,新华三历经艰辛。徐润安坦言,最大的挑战在于,需要从产品的预研立项、研发设计、生产制造、落地交付的每一个环节都要对齐。另外,还需要考虑如何以最小的代价,适配更多平台,缩短研发周期,更重要的是保持供应的稳定。
产品方案之外,业务模式创新方面,新华三打造图灵小镇生态平台,汇聚GPU厂商算力、行业场景,共同探索何种算力更适合特定应用场景、性价比如何,并提供试验场。以此形成算力验证、场景落地、商业闭环的生态链,对AI到底如何提升生产效率的灵魂问题做出回答。
不难发现,面向AI技术的迅猛发展,新华三通过“算力×联接”的核心理念,多元开放的生态策略,工程化落地能力,以及对AI普惠的坚定投入,凸显了其作为AI基础设供应商的核心地位。与此同时,也为国产算力生态提供一条从技术创新到商业闭环的可行路径。