♦ 参与单位
♦ 项目背景
随着AI技术快速普及,企业算力需求激增,但是当前用算模式存在明显痛点:传统私有化算力部署成本高、扩缩容不灵活,且算力硬件的技术迭代快,容易造成企业投资浪费;如果企业选择租用公有算力,则面临数据传输效率和数据安全等问题,比如当前大量数据依赖线下硬盘拷贝和搬运,传输效率低且存在隐私数据泄露风险。为破解企业用算面临的痛点,需要广域网络具备高吞吐、高弹性、广域无损等新特性,实现算力与网络的协同供给,满足用算企业数据入算、模型训练和推理等关键应用需求。
♦ 技术方案
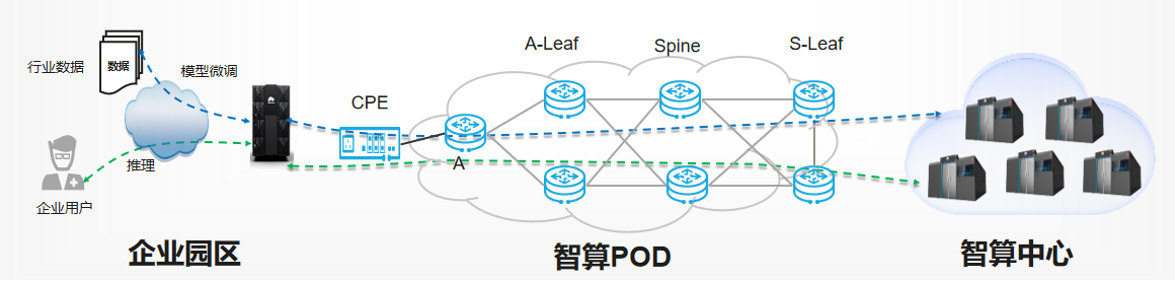
基于400GE弹性无损智算广域网络的算网一体服务方案,以"网络筑基、算力随选"为核心设计理念,依托IPv6+和RDMA广域无损等核心技术,打造AI时代运力基础设施--新型城域网智算POD,通过引入智算业务感知、租户级精准流控、深度负载分担、关键帧加速、400GE端口等新特性,实现智算业务的原生承载能力。
新型城域网智算POD采用Spine-Leaf架构建设,全域部署400GE高性能智算路由器,其中Spine设备作为网络核心枢纽,承担智算业务流量的全局转发与疏导,保障跨节点高速互联;S-leaf定位算力汇聚层,承担算力池的接入与调度;A-leaf定位业务接入汇聚层,负责各类业务流量的收敛与汇聚转发;CPE作为企业用户侧接入终端,提供企业与智算POD的专属接入通道。业务承载层面,CPE与S-leaf之间通过L3EVPN over SRv6 Policy协议承载训练、推理等智算业务流,全程精准识别RDMA流量,通过深度负载分担、精准流控及关键业务优先级保障机制,实现智算业务的高效、可靠转发。
♦ 创新点
在IPv6/IPv6+技术创新方面,本项目通过部署基于SRv6的深度负载分担、租户级精准流控等技术,在智算POD实现超百公里的RDMA无损传输,网络吞吐率超过90%,算效达到同数据中心的97%以上,为大规模分布式训推筑牢技术底座。
在商业模式创新方面,本项目提出以下三种算网一体服务模式:
1. 边云协同分布式推理服务,通过将模型分层部署于云侧和企业侧,实现数据不出域的协同推理,化解企业使用公共算力的安全焦虑;
2. 存算分离拉远训练服务,通过智算POD连接企业本地存储和云端算力,实现边训边传,提高模型训练微调效率,数据无需在园区外存储;
3. 弹性带宽入算服务,基于"任务量+时长"按需申请和弹性调度算力网络资源,破解传统带宽服务 "低带宽等不起、高带宽用不起" 的行业痛点。
♦ 应用效果及推广前景
当前算网一体服务已在某大型航运企业进行了应用试点,该企业应用包括两款大模型,一是基于Qwen-VL-32B的多模态船管大模型,通过人工智能实现航线优化节能、船舶智能运维;二是自研Hi-dophin大语言航运模型,提供智能问答、智能决策等服务。随着上述人工智能应用的深度落地,企业急需算力扩容以支撑业务增长。该企业依托智算POD实现浦东园区私有算力与110公里外临港公共算力的跨域互联,同步开通边云协同推理、存算分离拉远训练两项算网一体服务。在保障数据安全的前提下,企业通过公共算力实现弹性扩容,满足航运模型高并发推理和船管模型高效训练等需求。
在产业推广层面,本项目通过牵头智算网络相关国家/行业标准编制,推动网络技术升级演进,引领基于IPv6/IPv6+的智算广域网产业发展;同时本项目将推动公共算力服务规模化落地,构建"算力如水、随取随用"的普惠服务生态,全面赋能千行百业数字化转型。