Labs ����
������������թƭ���ֳ����߷�̬�ƣ�����������߶ȹ�ע������5G�����ķ�չ�������豸�������������ļ�������������Դ���ḻ����������������ָ��������ͬʱҲ���������ʶ��ͷ�ֹթƭ�����ݴ����ĸ��ӳ̶ȡ����������Ӫ�����ԣ���ͳ����թ�������������ã������ܹ��ڶ�ʱ���ڴ����������ݣ��Է�ֹ��թ��Ϊ�˽���������Ⲣ���õı�������ܺ��û����������һ������ͨ����Ϣթƭ�ķ�������ʵ��5Gʱ���´���������ȡ������ŵ�ͨ�����������û���ѧϰ�����������кʹ��á���������֤���÷�����ȷ�Կɴ�85%��
���ߣ�����������棬����³����
��������ͨ����Ϣթƭ��ɵ���ʧ�����������թƭ��ʽ�;籾������ͨ����Ϣթƭ���γ���һ���dz������ķ����ҵ���������йػ������㣬ͨ����Ϣթƭ��ҵ�ߴ��ϰ����ˣ����ҵ��ģ�Ѿ��ߴ�ǧ��Ԫ��Ŀǰͨ����Ϣթƭ�������г��ֳ���һЩ�µ�������
һ��թƭģʽ�¼������������������������������Ṥ��ѧ����թƭ�����ű������ò���������թƭ�ַ�����Ӫ�̵�ҵ����������©����ͨ��թƭ�¼������ý��ܺ���һ��������Ȧ�ף����˷���ʤ����
����թƭ�������ֶζ�������רҵ�������ſƼ��ֶεĽ����������ֶ��Ѵ���ԭʼ�ķ���������绰�ȷ�չ��ɨ�������ά��ֲ��ľ������������թƭ�ȶ�����վ�ȶ��������������������ͷ����ֶΡ�
����5G�����ķ�չ��ͨ�Ž���ø��ӱ�ݣ�����Դ��ø���������������Ҳ����ּ��������ơ����ô�ͳ����������ֶκ�ʶ�����������Ӧ����ز��ź���ҵ����������鲻�㣬����ʤ����
1 �о�Ŀ��
������������5G�ķ�չ����Ӫ�̲ɼ�������Դ���ḻ����������������ָ������������թƭ������ʽҲ��������ð���������“�²�����˭”�ij���թƭ��ʽ���������������վ��������վ�������ʼ��ȶ��ֺڲ��ֶε�����թƭ��ʽ����ˣ�ͨ����Ϣթƭ�������Ѽ���Ԥ����Ҳ��ͨ����Ϣթƭ������������˸���Ҫ�����ܹ����ô����ݼ������ڶ�ʱ���ڴ�������ͨ�����ݣ��������û���ѧϰ������ģ����ʱ��թƭ�����������кʹ��á�
Ŀǰҵ����Ҫ��ɧ��թƭ�绰ʶ�������¼��֡�
��1����������������İ���绰�������ݣ�ʹ����Ȼ���Դ�����ȡ��Ϊ������������ַ��û�ͨ����˽��Ӱ���û���֪�Ȳ���Ӱ�졣
��2����ֵƥ�䣺�����к����ֶ�ƥ�估�����Ƶ����ֵ������Ͷ���������ݶ�����֤������ɾ����ֶ���������ͨ�û����뱻���У�������ʶ��������к����ֶ�������թƭ�绰����Ͷ�����������٣�ֻ������թƭ�绰����¼��
��3��������㣺����թƭ�绰�غ����к�������ƶȣ�������ȷ�ϵ�թƭ�绰����ָ��ֵ����ƥ�䣬������ɹ��Ӫ���ȵ绰��թƭ�绰��Ϊ���ƣ��Ӷ����е��������ͨ����Ϣթƭ��ʽ��䣬��Ծ�ڶ̣�������õ���Ч�ܿء�
��5G�����£��������������������ٶȳ�ָ��������ʶ��ͷ�ֹթƭ�����ݴ����ĸ��ӳ̶�Ҳ��֮����
������Դ���棺����5G �����ģ���ṩ������������������ݿ���������ܹ��Ӷ��ͨ������ȡ�������ݣ���֧�ֶ������ݸ�ʽ��
��ʱЧ�Է��棺Ϊ�˸���ʱ��Ч��ʶ��թƭ��Ϊ����Ҫ���뼶�����Զ�Ӧ����ǧ�����û���ѧϰ����
��ȷ�Է��棺Ϊ����ֹ��թ�Խ����û����ײ����ݿ���Ҫʵʱ������ǧ�����ԣ�������ʵʱ���ܺ����¼������������û���Ϊ������λ�á��豸��Ϣ�ͽ������͵ȡ�ʹ�����û���ѧϰ�㷨������Щ��������ȷ����Ϊ���бȽϣ������¼���ʶ�����ϡ����ѡ�
�����������⣬���������һ������ͨ����Ϣթƭ�ķ����������ô������е�Hadoop�����ʵ��5Gʱ���´���������ȡ������ŵ�ͨ����������������XGBoost�㷨��ͨ���Ժ����ڰ�������ѧϰ������һ��թƭ����ʶ��ģ�ͣ��ܹ���ͨѶ��Ϣթƭ���п������кʹ��á�
2 ϵͳ�����ܹ�
����ϵͳ�����ܹ���ͼ1��ʾ��ϵͳ��Ҫ����թƭ�绰ʶ���ܺ��̶��ж���������Ⱥʶ�������ģ�顣���������������쳣������Ϊ���¼�����ʶ��թƭ���룬����ͨ��������Ϊ��ʶ��ͨ����Ϣթƭ�ܺ��ˣ������ҵ����Ӫ֧��ϵͳ��BOSS���������û���ʷͨ�����ݡ��������ݺ��������������г̶Ƚ��зּ���
��թƭ�绰ʶ���㷨����Ҫ�漰�����������е������ֶΣ���ȡ�û���ͨ���쳣��Ϊ����ɸѡ��ͨ���쳣��Ϊǰ���ͨ����Ϊ��������û��й�ͨ�������к���ͱ��к�����б�ǣ���Ϊ����թƭ�绰���ϡ����������ݡ�BOSS��������ȡ����թƭ�绰��ȫ��ͨ������������CART���������쳣����ʶ�������Ƿ�Ϊթƭ�绰�����б�
���б�Ϊթƭ�绰����ɸѡ����թƭ�绰�й�ͨ����Ϊ�����к��룬����ͨ����Ϊ�����б������û��ܺ��̶ȡ�
����������ܺ����û�ͨ����������Ϊ��������Ⱥ���л��Ӷ�ʵ�ֶ������û����г̶ȷּ���
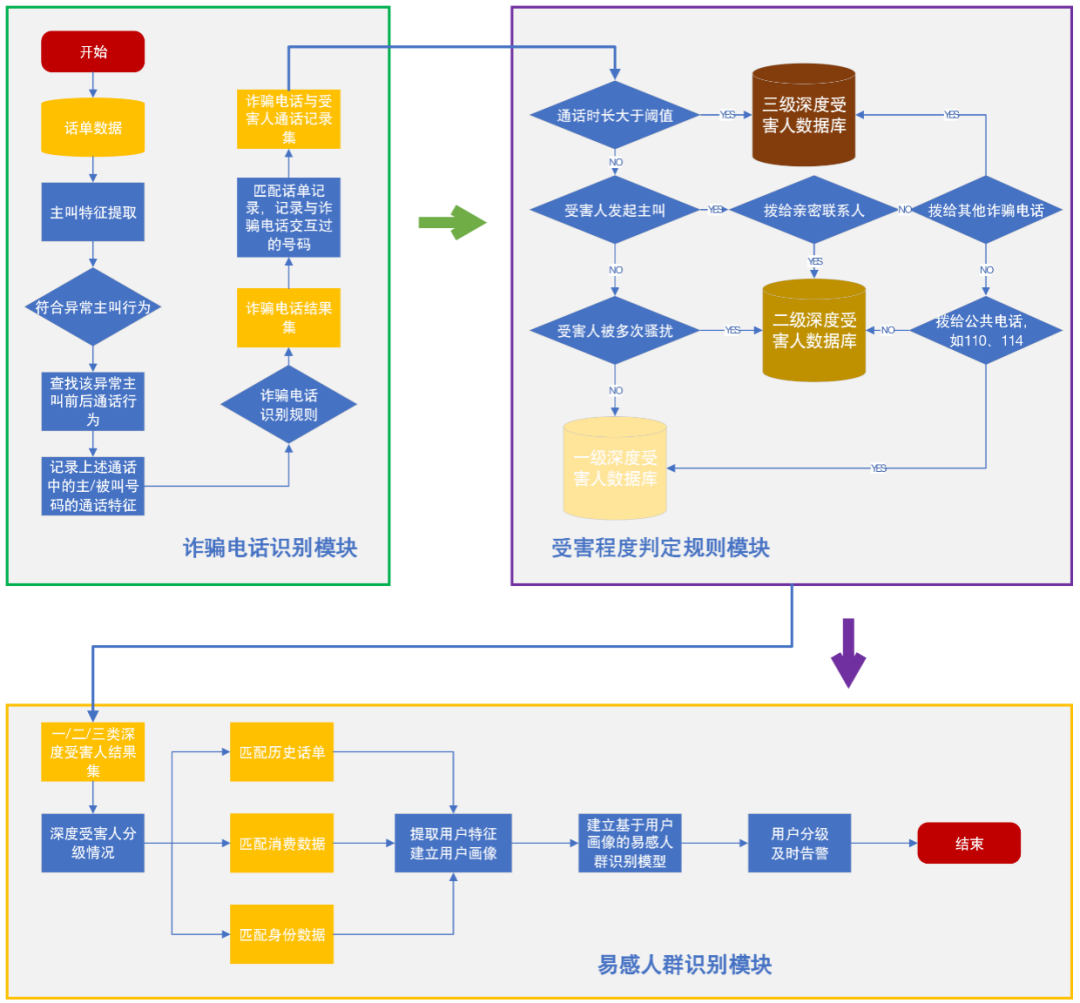
ͼ1 ����ϵͳ�����ܹ�
3 ���ʵ��
3.1 թƭ�绰ʶ��ģ��
��ģ�����ھ�ʶ��թƭ�绰�����ڱ������������Ҿ����쳣ͨ���������û�������CART������ģ�ͽ���ʶ�𡣶����ڻ�Ծ�ڶ̻��³��ֵ�թƭ�绰�������û��쳣���м���ǰ��ͨ����Ϊ�¼���ģ�ͽ���ʶ��
3.1.1 ��ǩ������ȡ���������
���ڴ����ѱ�ǵ�թƭ/ɧ�ŵ绰������ȡ���ѡ���˲�����������ķ�ʽ�����������������ύ��360���ٶ�����վ��������Щ��վ���еĺ������������������м�⣬��ȡ�������ֻ����ֱ�ǵ�����թƭ/ɧ�ź�����Ϣ������Щ���ɺ�����Ϣ�������ݿ�����ģ��ѵ����
�����û��ڸ����ֻ����ֱ���ֻ�����ʱ�IJ�ȷ���ԣ��������·�����������ǽ����ȷ�ԡ�
��1����360�Ͱٶȶ�ͬһ�����ǣ��õ��Ľ����ͬʱ�����øñ�ǽ����
��2����360�Ͱٶȶ�ͬһ�����ǣ��õ��Ľ������ͬʱ���Ըú�������Ϊ�����Ͻ��з�����ѡ����Ϊ�����������ǽ���ȽϷ��ϵ���Ϊ���ձ�ǽ���������1822553****���ڰٶ��ϱ��Ϊɧ�ŵ绰����360�ϱ��Ϊ�������룬�����ݿ��з����˺���ͨ����Ϊ������֪���ú�����һ��������ͨ������14�Ρ�������1��������ϵ�˸���14�����������ϵ�ظ���14������ͨ������0���ز���0����ϵ��/ͨ����������1�ȣ���̫���������ֻ��û���ͨ����Ϊ����˽��ú�����Ϊɧ�ŵ绰��
3.1.2 ����ѡ������ͳ�Ʒ���
���ǵ�թƭ/ɧ�ŵ绰����һ���绰��������绰��ͨ����Ϊ���������绰֮���Ȼ����ijЩ���𣬶�����Щ�绰��Ϊ���У����ѡȡ����ͨ����Ϊ��������������ͨ���������������ͨ�������������ʡ�������ϵ�˸��������������ϵ�˸��������������ϵ�ظ���������ͨ��Ƶ�ʡ�����ͨ��ʱ��������ͨ���������ز��ʡ����վ������ϵ��/ͨ�����������ȣ�����ͳ�Ʒ�����
��ijһ��ij��ʡ���������ݽ���ͳ�Ʒ���������ͨ������ķ�ʽ��4�ֺ������͵ĸ���ͨ��������ͳ��ֵ���о���չ�֣����1��ʾ��
��1 4�����ͨ������ͳ��ֵ
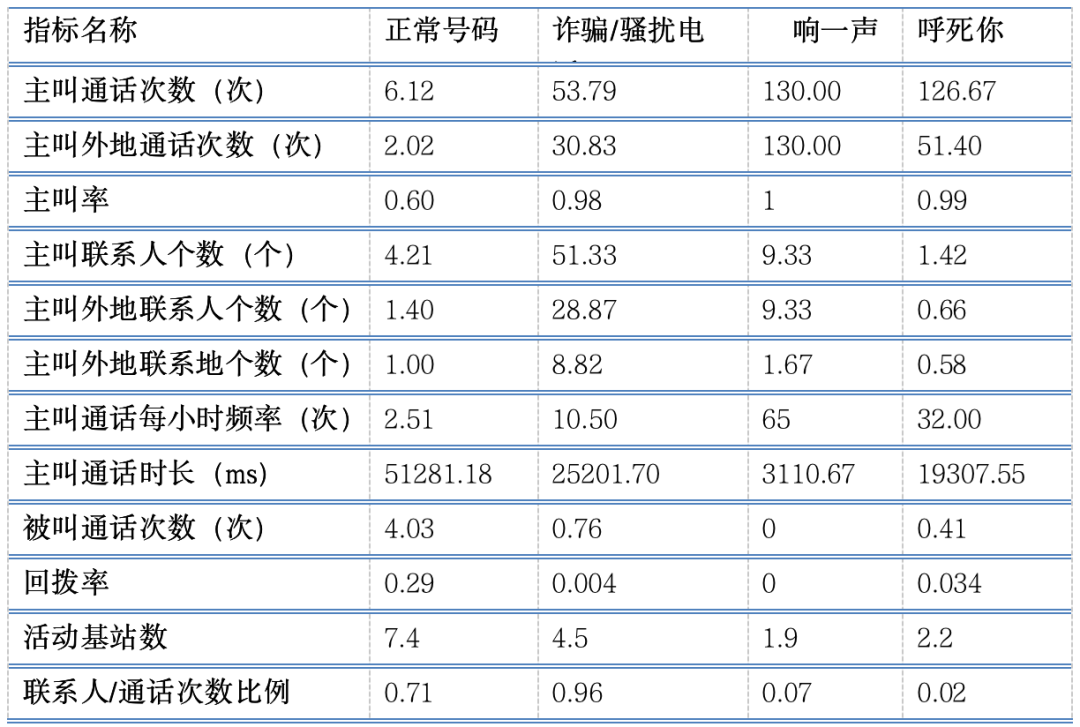
ѡ��ͳ�Ʒ����½�����������������ͨ�������������ʡ����������ϵ�˸��������������ϵ�ظ���������ͨ��Ƶ�ʡ�����ͨ��ʱ�����ز��ʡ���ϵ��/ͨ��������������������������һ��������������ͼ2ֱ�۵�չ����4�ֺ��������������ϵ�����

ͼ2 4�������������
������ͳ�Ʒ�����������������������ͼ��֪���������롢թƭ�绰����һ������������ijЩ�����Ͼ����������𡣾������2��ʾ��
��2 4�������Ҫ����
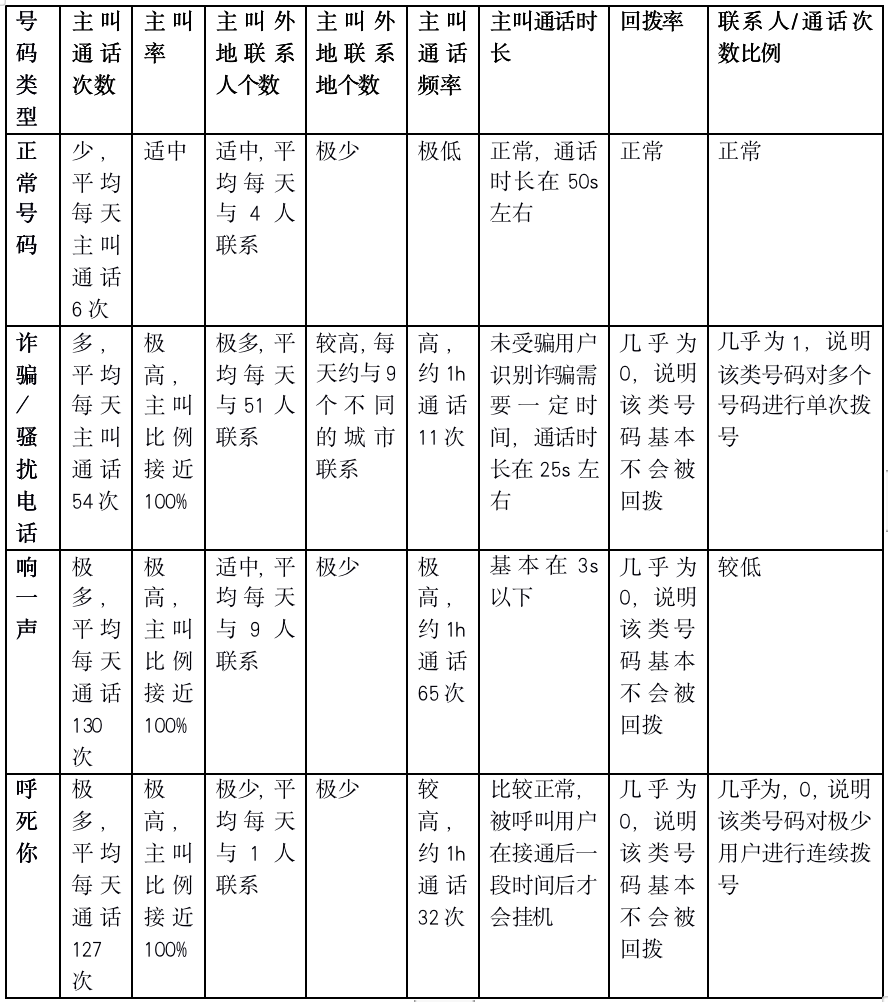
�ӱ�2�ɵ����½��ۡ�
��1��թƭ/ɧ�ŵ绰����һ����������������ͨ�������������ʡ�����ͨ��Ƶ�ʶ��������������룬���ڻز����ϴ������������롣
��2����һ���������������թƭ/ɧ�ŵ绰����ͨ���������࣬���������ϵ�˸������٣�ͨ��Ƶ�ʸ��ߣ���ϵ��/ͨ�������������١�
��3����һ������ں����㡢թƭ/ɧ�ŵ绰������ͨ��ʱ��������������
Ϊ��һ��������4����룬��������������������
3.1.3 ����CART��������թƭ�绰ʶ��ģ��
������ͨ�������������ʡ����������ϵ�˸��������������ϵ�ظ���������ͨ��Ƶ�ʡ�����ͨ��ʱ�����ز��ʡ���ϵ��/ͨ�����������ȹ�8��������ΪCART��������������������������Ϊ5��������Ϊ100��Ŀ��������0�����������롢1����թƭ/ɧ�ŵ绰��2������һ����3���������㡣
ͨ���������õ��ľ��߹����Ԥ�����ݲ��øù������Ԥ�⣬�ó�����թƭ/ɧ�ŵ绰�����1��
3.1.4 ����XGBoost������ģ��
����թƭ���������û����ȷ�Ľ��ޣ������CART�����������թƭ����桢��ͨ�û�������1������2�ĺ��룩���н�һ��ʶ�𣬼�������ģ�͡�����թƭ��������Ϊթƭ��ɧ�Ż��û��ٱ��ģ���漴������Ϊ�н���������ȡ�
�������ǩ������������£���label0-1������������ǩ�ޱ�ǵĺ��룬label1-1������������ǩ���Ϊ"ɧ��" �� "թƭ"�ĺ��룬label2-1������������ǩ���Ϊ"����" �� "�н�"�� "���" �� "����"�ĺ��룬label1-2�������������ݱ��Ϊ��ͣ��Ӻڵĺ��롣
�ڰ��������������£���������0������label0-1���� + ��ϵ����С��20�ķ�label1���룬��������1������label1-1 ����+ label1-2���룬��������2������label2-1���롣
����XGBoost�����IJ������3��ʾ��������������ģ��Ĭ��ȡֵ������������
��3 �������������
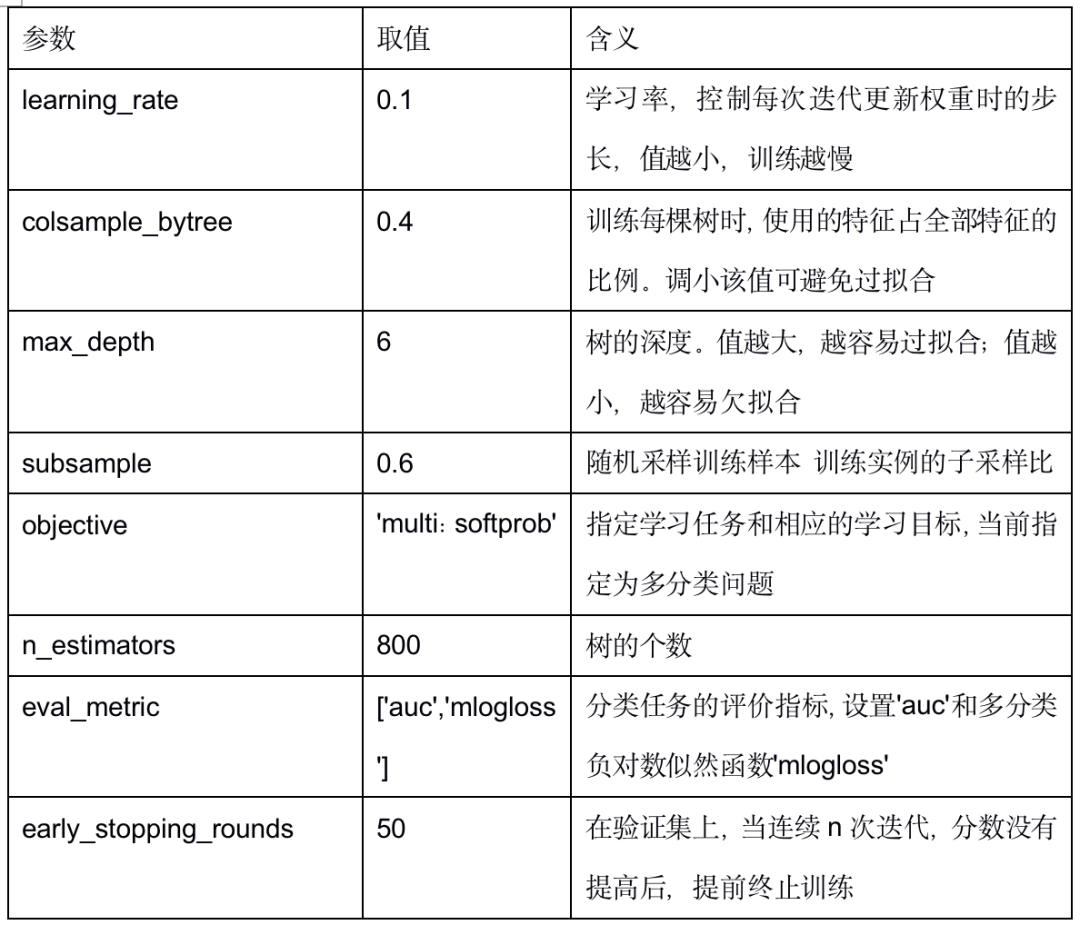
��ȡ������е�����3������4����������ģ���������ϲ�Ϊ�����2��
3.1.5 �����¼�����թƭ�绰ʶ��ģ��
���ڻ�Ծ�ڶ̻��³��ֵ�թƭ�绰����ʶ�𡣸���ͼ3��ʾͨ����Ϣթƭ����ͼ��һ�㵥��һ��ͨ�����������թƭ���̣���������թƭ�Ż��Ա���зֹ���ͨ�����ͨ������ܺ������Σ��Ӷ����թƭ��
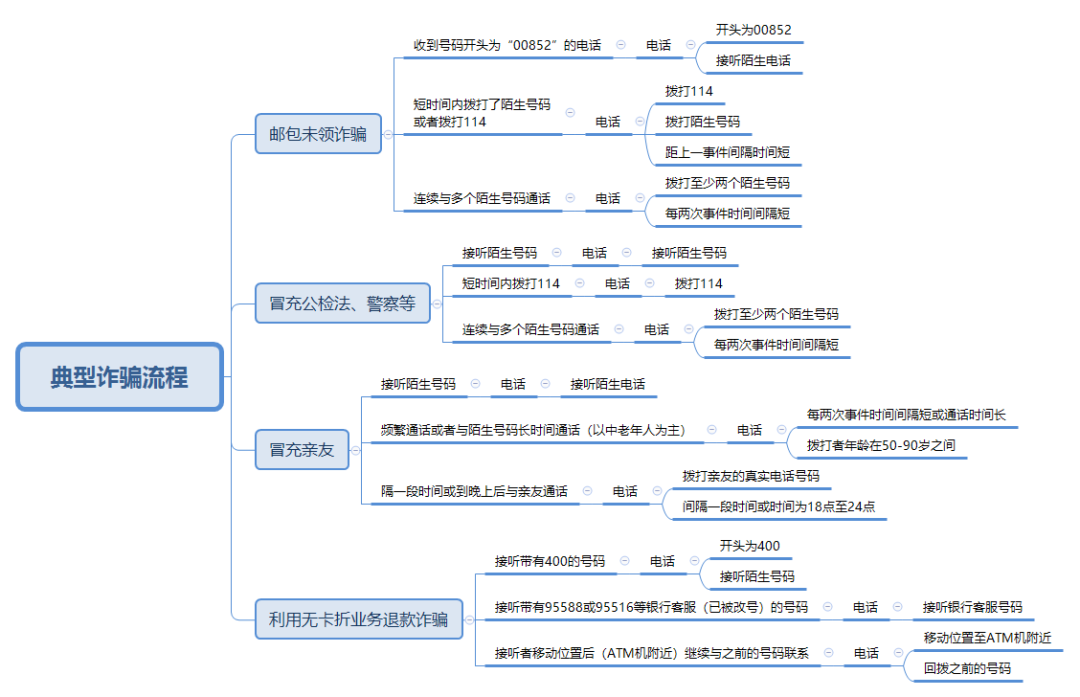
ͼ3 ͨ����Ϣթƭ����
���û��Ƕȶ��ԣ����û��ӵ�թƭ�绰��ɶ�ʱ����ʶ�𣬲����к���ͨ����Ϊ��������ʱ����ʶ��թƭ�绰���û��������թƭ���뼰���������н�����Ϊ����ͨ��ʱ��ϳ�����˿ɴ��û��쳣������Ϊ�Ƕ����֣�ͨ���ھ��û��쳣ͨ����Ϊ����λ����թƭ�绰����ͨ��թƭ�绰ʶ�����թƭ�绰���о�ʶ���û��쳣��Ϊ��Ҫ�����¼��֡�
��1������û���ʱ���ڽӵ���һ��İ���绰��
��2���û��ڽӵ�ijİ���绰�����ڷ���������Ϊ���Ҷ���Ϊ�����绰��
��3������û��ڽӵ�ijİ���绰�����ڷ���������Ϊ�������ж���Ϊͬһİ���绰��
���й����绰ָ110��114��95550�ȿͷ��绰��İ������ָ30����δ������û��й�ͨ����Ϊ�ĺ��룬���ų����������绰��
�����������쳣��Ϊʱ����¼��İ���绰�������Ϊ����թƭ�绰��ͨ����ѯ����թƭ�绰�����BOSS���ݣ�ƥ�������թƭ�绰��ͨ����Ϊ��������Ϊ�ȣ����4��ʾ��
��4 �¼���ģ����������

թƭ�绰��������ȷ�թƭ�绰�����������и�Ƶ�������ϵ��ռ�ȸߺ�ͨ��ʱ����β�ͷֲ����ص㡣Ϊ��һ����ȷ�ж�թƭ�绰��������Ⱥ���ⷽ�����о�ʶ��
���ڶ�������թƭ�绰���������Ի�����Ƿ�Ϊ����թƭ�ı�ǩ����˲����ලѧϰ�����е���Ⱥ���⼼�����ҵ�����թƭ�绰�е��쳣�㣬��Ϊթƭ�绰��������թƭ�绰��������ΪX��ͨ�������������ܶȸ����������Ⱥ�ĵ÷ֽϸ�ǰN��������Ϊթƭ�绰��թƭ�绰ʶ�����ľ����㷨�������¡�

ͨ���¼���ģ�͵ó�����թƭ/ɧ�ŵ绰�����3��������թƭ/ɧ�ŵ绰�����2���кϲ�ȥ�صõ����Ľ����4��
3.2 �ܺ��̶��ж�����ģ��
�������û���թƭ�绰ͨ����������ܺ��̶Ƚ��зּ���
���������ѱ�ʶ������ж�Ϊթƭ�绰�ĺ��룬�Ա�թƭ�绰���й����û�����ϸ�֡������û���թƭ�绰��ʶ���������в����ԣ������û��ڿ��������жϲ��ҵ������������ƭ�����Խ�С���������û����ڽӵ�թƭ�绰�������ѡ�114�Ⱥ������ȷ�ϣ�Ҳ���ڲ����û�һ���ڱ����ɧ�ŵ�����������Ҫ�Զ����ܺ��˺�����Ϊ�������зּ������ܺ��̶��ж�����ģ����ʾ��
�ܺ��˷������еĶ����Ϊ�����ˡ�թƭ�绰�������绰��İ������4�ࡣ
��1��������ָ��������ͨ����¼�У������������ж��������ϵ�ˡ������������ж�������ָͬһ�����أ���30�����ܺ���ͨ��������5�εĺ��롣�ܺ��˽ӵ�թƭ�绰���������Լ��������ˣ�����Ϊ����һ���̶���������թƭ�绰�����ٴ������Ѻ�ʵ���ʽ������2������ܺ������ݿ⡣
��2��թƭ�绰ָ�ѱ�ʶ������б�Ϊթƭ�绰�ĺ��롣�ܺ��˽ӵ�թƭ�绰�������������Ҫ���ܺ��˲���һ���º��룬�ú����Ϊթƭͬ�����Ϊ�ܺ���������ȫ������թƭ�绰���ʽ������3������ܺ������ݿ⡣
��3�������绰ָ110��114��95550�ȿͷ��绰���ܺ��˽ӵ�թƭ�绰������ʱʶ����110��95550�ȹٷ��绰���к�ʵ������������Ϊ���յ�թƭ�����Խ�С���ʽ������1������ܺ������ݿ⡣
��4��İ������ָ���������ˡ�թƭ�绰�����绰֮��ĺ��룬��������ϵ��Ƶ���������˻�δ��ǵ�թƭ�绰������һ����ƭ���ܣ��ʽ������2������ܺ������ݿ⡣
���ܺ����ڽӵ�ɧ�ŵ绰��δ�������У�����ܺ����Ƿ�Ƶ��ɧ�ţ����ڴ˼�¼ǰ�ѱ����ɧ�ţ��������2������ܺ������ݿ⡣��Ϊ����ɧ�ţ��������1������ܺ������ݿ⡣
�ڷ�������ܺ��˶���ǰ���£��ٶ��ܺ��˽���ϸ�֣�������1/2/3������ܺ��˵Ķ��塣
1������ܺ��ˣ���թƭɧ�ŵ绰ͨ��ʱ���϶̣����ܺ���δ��������Ҳδ�����ɧ�š����ܺ��˷������У����ж���Ϊ110��95550�ȹ����绰���ܹ���ʱ��ֹթƭ��
2������ܺ��ˣ���թƭɧ�ŵ绰ͨ��ʱ���϶̣����ܺ������ж���Ϊ������ϵ�˻�İ���绰�����ڱ�ƭ���ܡ����ܺ����ڶ��������İ���绰�Ķ��ɧ�š�
3������ܺ��ˣ���թƭɧ�ŵ绰ͨ��ʱ���ϳ�������10min�����ܺ����ڽӵ�թƭ�绰��������������һ��թƭ�绰����ƭ�����Ժܴ�
����Ӫ�̽Ƕȣ�ģ���ܺ��˵���ƭ�������Ӷ��ܹ���Դͷ�϶Ե���թƭ�ܺ��˽��������ͼ�أ�Ϊ�˶��û�����������Եĵ���թƭ������������������Ⱥ����ͷ���ģ�顣
3.3 ����Ⱥʶ��ģ��
��ģ�����û�ͨ����������Ϊ��������Ⱥ���л���ͷ��ࡣ��թƭ�绰ʶ��ģ�����е�թƭ�������ݣ�������թƭ������ϵ�����û����оۺϣ��ó����б����û���ͨ�����ͣ����ܺ���ʶ��ģ����ܺ��̶��ж�ģ���õ�1/2/3���ܺ��ˣ��ֱ���Ϊ1/2/3������Ⱥ����û�������κ�թƭ�绰�ֺ����û����ΪDZ������Ⱥ������������������Ŀ���������5��ʾ��
��5 ����Ⱥʶ��ģ��������������Ŀ������

��������1/2/3������ܺ��˺�DZ���ܺ��˵��罻��Ϣ����Ϊ��Ϣ�������ݣ���4������Ⱥ�����Ϊ�������ݼ��ϣ����û���ѧϰ�е�kNN�㷨������г̶ȷּ���������û�б�ǩ�����û����ݺ������ݵ�ÿ������ֵ�������������ݶ�Ӧ������ֵ���бȽϣ�Ȼ���㷨��ȡ�����������������Ƶ����ݵķ����ǩ������ʵ�ֲ������¡�
����1����������֪�Ĵ�ñ�ǩ���û����ݷŵ�Hadoop��HDFS�ϣ��ֱ���Ϊѵ�����ݺ��������ݡ����ݵı�ʾ��ʽ���£�A�û����Ա�ʾ�ɣ�xA0, xA1, ……xA10����B�û����Ա�ʾ�ɣ�xB0, xB1, ……xB10��������xA0��ʾ�û�A��ϵ������xA1��ʾ�����ϵ�˸������Դ����ơ�
����2��ͨ��Map��������������ݵĽڵ㵽ѵ�������ڵ�֮��ľ��룬���о�����㷽����������Mahalanobis���빫ʽ�����վ������������������Ľ����ΪMap����������ΪReduce��������������
����3����Reduce�����У�ѡȡ�뵱ǰ�ڵ������С��k���� ����ȷ��ǰk�����������ij���Ƶ�ʣ����շ���ǰk�������Ƶ����ߵ������Ϊ��ǰ���Ԥ����ࡣ
����4���������������kNN�㷨�Ĵ����ʣ�ͨ������k�Ĵ�С���Է��������е��š�
����5�������µ��û����ݣ����ȼ���������ֵ��Ȼ���ղ���2��3����������Ⱥ�ּ����
4 ������
���������һ�ֶ�ͨ����Ϣթƭ��Ϊ����ʶ��Ͷ�����ܺ��˽��з���˫�ط����ķ������÷�����Ͽɻ�֪�Ŀ����������û���ѧϰ�㷨��ʶ��թƭ�绰��ͬʱ�ܹ������û���İ���绰��ͨ����Ϊ��ƥ���쳣ͨ����Ϊģʽ������������թƭ����ƥ�������DZ���ܺ��ˣ���ʱ���벢���û�������ʾ�澯�������û��Ƕȣ���ͨ����Ϣթƭ�г̶Ƚ��зּ���
Ϊ���ܹ�����Ч��ʹ�������еķ�������ֹ5G�绰թƭ����һ����Ҫ��������������ʶ�Ⱥ�ʶ��ĸ����������Լ�Ӧ��5G�绰թƭ������������������
�����
[1] ������. ����թƭ�������ϵͳ�������ʵ��[D]. �����������ʵ��ѧ��2019.
[2] ����.����������թƭȫ��ָ��[M]. �Ϻ����Ϻ�����ѧԺ�����磬2016.
[3] �.ͳ��ѧϰ����[M]. �������廪��ѧ�����磬2012.
[4] ��Դ.����ϵͳ[M]. �����������ʵ��ѧ�����磬2008.
[5] ����.�����㷨���Զ�ʶ���ð�쵼թƭ�绰��Ӧ��[J].�ƶ�ͨ��,2019(06).
[6] .����ƽ,����ũ.���������������թƭ֮�羳����[J].����ѧ��,2018(03).
[7] ����֮,�����,��ˬ,��.����SVM�ĵ���թƭ��Ϊ����ʶ��[J]. ����, 2017(12).