自 2024 年起,大模型研发重心逐步从单纯的预训练转向高质量的推理。如今,模型不仅要“会看”,更要“会想”。以 OpenAI 的 o1 为代表的一批推理模型,通过多步推理显著降低错误率,宣告了“推理时代”的到来。2025 年初,DeepSeek 的问世将这一趋势进一步放大。DeepSeek 通过多项工程与算法创新——包括 MOE(多专家并行)、多 pipeline 流水线掩盖,以及 MLA(Multi-head Latent Attention)低秩压缩以降低 KVcache 数据量——有效缓解了大规模推理的瓶颈,显著提升训练与推理性能,降低使用成本,从而成为普适大模型的典型代表。
在 RAG 等技术的推动下,推理正朝长序列输入方向演进;与此同时,从事单纯预训练的厂商数量明显减少,行业竞争焦点正在向“高效、低成本的推理能力”聚拢。谁能在最短时间内以最低成本获得更高的推理收益,谁就能掌握智算市场的“屠龙刀”,赢得更大的市场与利润空间。AI 的未来将由推理驱动,而推理的胜负,取决于谁能把性能做到极致并把成本压到最低。把握这一点,就是把握未来智算市场的话语权。
AI集群推理对算力基础设施的要求
提到推理的基础设施,就不得不提Prefill与Deocde分离部署方式,我们先来了解下什么是prefill和decode。
● Prefill(预填充)阶段:处理用户的全部输入,将相关信息写入 KV cache,并生成第一个 token。每个推理任务中,Prefill 只执行一次。
● Decode(解码)阶段:以自回归方式逐步生成后续 token。举例:若输出序列长度为 1024,则 Prefill 产生第 1 个 token,Decode 需执行剩余的 1023 次生成操作。
Prefill阶段的特征是计算密集(Compute bound)型 ,需要遍历模型所有层进行前向计算,大量矩阵乘法使得算术强度(FLOP/Byte)很高。GPU/加速卡的算力利用率通常可达 80%–90%,而 HBM(片上高带宽内存)访问相对较少,带宽利用率仅为个位数百分比,带宽并不是瓶颈。因此可通过减少 HBM 带宽或容量,采用更低成本的 HBM 来降低总体成本。
Semianalysis 对HBM的成本有详细的分析,如下图1所示:在NVL72的GB300中,HBM成本占比高达61%,在计算密集型的prefill阶段,HBM有大量的时间都处于空闲状态,这是对昂贵的HBM的资源极大浪费!
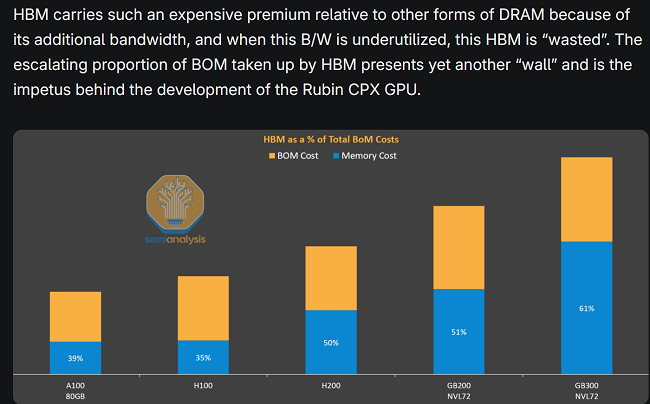
图1 : HBM成本占比
而Decode阶段的特征是访存密集(memory bound)型,每生成一个 token 都需从 HBM 拉回 KV(通常为几十 MB)到芯片处理单元(SM),带宽利用率可达 70%–90%。Decode 阶段频繁进行 batch 组建与 KVcache/参数读取,因此访存带宽直接决定了延迟与吞吐,成为关键性能瓶颈。
因此,在实际部署中,将 Prefill 和 Decode 分别放到不同类型的硬件节点(例如“算力节点”与“带宽节点”)可以显著提升整体吞吐并降低延迟;算力节点(Compute optimized):为 Prefill 提供高 FLOPS、较低 HBM 要求的硬件配置,降低成本。带宽节点(Memory optimized):为 Decode 提供大带宽、高容量的 HBM,消除访存瓶颈,提升单 token延迟和吞吐。 下图2为微软&华盛顿大学研究成果,通过PD分离,实现推理性能的大幅提升(吞吐提升240%),而成本基本上没有变化。

图2 : 微软&华盛顿大学PD分离部署研究结果
英伟达 Rubin CPX:为 Prefill 而生,推理成本迎来新拐点
2025年9月9日,在英伟达 AI 基础设施峰会上,英伟达推出了一款专为 Prefill 阶段设计的 GPU——Rubin CPX。英伟达超大规模与高性能计算副总裁 Ian Buck 在发布会上进行了介绍(官方活动页:https://www.nvidia.com/en-us/events/ai-infra-summit/),Rubin CPX 面向的是日益增长的长输入序列场景,英伟达计划于 2026 年底将其推向市场。下图3是Rubin CPX与英伟达主流算力卡的对比,针对 Prefill 阶段的特点(计算密集、带宽需求低),Rubin CPX 做出了几项调整:FP4 峰值算力约 20P,约为 R200 的 2/3 左右,将昂贵的 HBM 替换为更低成本的 GDDR7,显存从 288GB 缩减到 128GB。
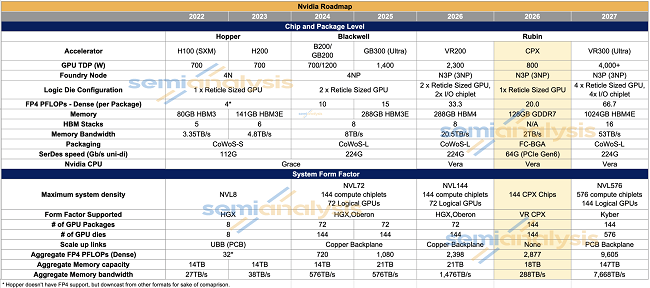
图3:英伟达不同系列GPU芯片对比
其中变化最为明显的是显存的类型发生了变化,我们在前面章节提到,prefill阶段是计算密集型的,访存的次数比较少,使用昂贵的HBM会造成资源的闲置浪费,通过将显存切换为价格更为便宜的GDDR,降低访存带宽,进一步降低了prefill阶段的硬件成本,而性能基本不会有损失。除了显存替换外,CPX 还取消了 NVLink 和 NVSwitch 等用于大规模 scale up 的互联硬件,从而进一步压缩了扩展成本。
Rubin CPX 提供两种机框配置形式(图4):单框 144 个 CPX,以及 144 个 CPX 与 72 个 R200 组合同框。在这些配置中,CPX 更依赖于 scale out(横向扩展)网络来连接各个芯片,而不是传统的高成本 scale up 互联。
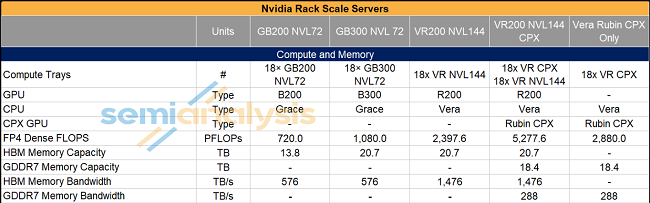
图4:英伟达机架服务器介绍
这意味着在未来的推理集群架构中,低成本的 scale out 网络将变得愈发重要:通过横向扩展并结合合理的调度策略,能在保持吞吐的同时压低总体拥有成本(TCO)。
与 Rubin CPX 同路:昇腾950PR 的算力带宽平衡策略
在华为全联接大会 2025 上,徐直军发布了 Ascend 950PR/950DT 以及 Ascend 960、970 系列产品。其中,Ascend 950PR 是专为 Prefill 阶段设计的算力卡,其设计思路与英伟达的 Rubin CPX 非常接近——通过有针对性的资源配比来降低 Prefill 的硬件成本。相较于面向更广泛场景的 950DT(HBM 带宽 4 TB/s),950PR 将显存带宽降至 1.6 TB/s,HBM 容量从 144 GB 缩减到 128 GB,进一步降低了Prefill阶段的成本。未来,通过scale-out网络连接950PR服务器形态,组成Prefill集群,进一步降低scale-up互联成本,会是一个比较好的选择。
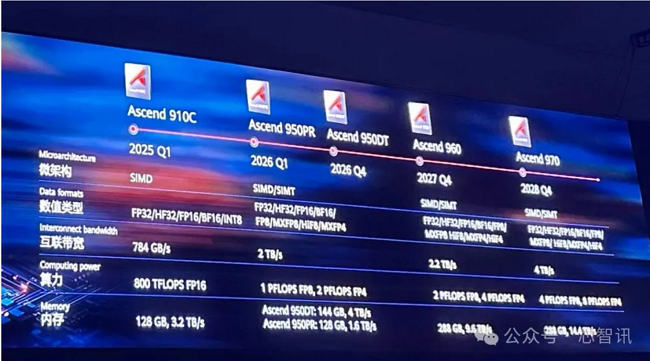
图5:华为发布昇腾950系列产品
异构算力是未来趋势,推动scale-out网络升级
昇腾 950PR 与英伟达 Rubin CPX 在思路上高度一致——在 Prefill 场景下牺牲部分带宽和显存容量,换取更低的硬件成本与更高的性价比。由此可见,按推理阶段选用不同算力卡已成为明显趋势——例如将 CPX/950PR 用于 Prefill阶段,把 R200/950DT 或 Cloud Matrix 384 用于 Decode阶段。
实际上,某大型互联网公司已经实现异构算力部署:用 NVIDIA 卡构建 Prefill 资源池、用超节点(高带宽实例)构建 Decode 资源池。Prefill 阶段获得高算力密度并降低扩展成本;Decode 阶段依靠超节点提供低延迟和大带宽,满足对实时性(TPOT)越来越苛刻的要求。华为云的研究论文也给出相似方案(如图6):用昇腾 A2服务器 做 Prefill、昇腾CloudMatrix384超节点做 Decode,以在推理场景中实现更优的性价比。

图6:《 xDeepServe: Model-as-a-Service on Huawei CloudMatrix384》
当前英伟达在算力上仍然领先,但国产 XPU(如昇腾、寒武纪、摩尔线程)正在快速崛起,形成百花齐放的格局。不同算力卡各擅所长,组合异构节点可以在成本与性能间取得更好平衡。在这种架构下(图7),scale out 网络需要承载大量 KV cache 和模型参数等流量,这对scale-out网络也提出了新的要求:
(1)多种速率与接口兼容:需要支持 200G/400G/800G 接入,甚至同时承载存储流量,未来可能还会复用 XPU 网卡以获得更低延迟与更高带宽。
(2) 无阻塞、高可靠的通信:异构算力间的通信模式复杂,网络必须保证无阻塞通信,解决负载均衡、拥塞头阻等问题,避免影响推理延迟与吞吐。

图7:异构算力互联架构
异构算力浪潮来了,scale-out网络准备好了吗?