5月16日,中国信息通信研究院(以下简称“中国信通院”)在江西省南昌市成功举办 “全光运力·毫秒用算”专题研讨会。中国移动研究院集团级首席专家孙滔博士出席并分享新一代AI Native基础网络技术体系技术创新和实践,提出以全光网络为底座推动AI与网络深度融合。

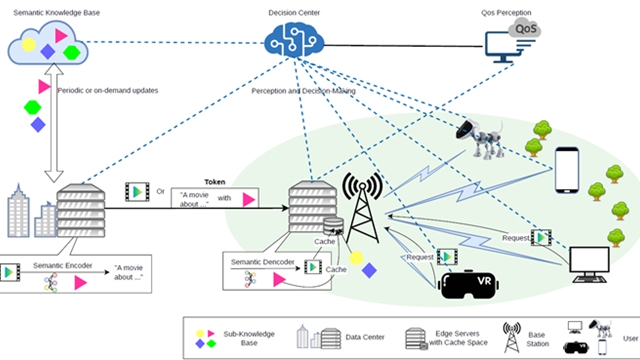
孙滔指出,大模型向“预训练+后训练”双轮驱动演进,AI普惠推高算力需求且呈现向分布化延伸趋势,对网络提出大带宽、高吞吐、低时延的接入需求。为此,中国移动构建新一代AI Native基础网络技术创新体系,聚焦算效提升、广域互联和垂直优化三大方向,为AI发展筑牢网络根基。
在网络传输方面,孙滔强调要持续提升网络互联能力,向更高带宽、更高吞吐迈进,并持续完善智算网一体调度能力,朝着更实时、更综合的方向迈进。此前,中国移动提出了基于QPSK调制、130GBd超高速光器件、C6T+L6T宽谱的400G新型骨干全光网技术体系,创下多项长距传输纪录,并完成首次400G集采部署,贯通“东数西算”工程八大枢纽,入选2024年央企“十大超级工程”,为千行万业的毫秒用算构建坚实的高品质全光运力底座。
针对智算场景,中国移动提出无损智算OTN(HIC-OTN)技术体系,立足高吞吐和无损,从超大带宽、超高可靠、超低时延三方面构建面向智算中心的新型OTN技术体系。在哈尔滨完成的百公里跨智算集群、千亿参数PP拉远训练现网试验显示,该技术可实现等同单节点训练效率98%以上的高效协同训练。
“要有康庄大道,也要有赛车速度”。在网络协议和组网方面,中国移动提出了抗损广域高吞吐技术“uRDMA”,克服传统广域数据传输技术受协议设计、算法实现等限制存在性能瓶颈,实现“数据快递”业务在天文观测、基因测序、云间数据同步等多场景的测试和试商用。而在算网协同方面,通过原创的“算力路由(CATS)”感知业务的算力资源消耗、吞吐时延等性能指标,结合对模型能力的特定要求,实现网络选路与算力节点选择的综合最优路径计算,显著降低业务端到端时延,提升算网资源利用率。
孙滔表示,中国移动将以全光网络为底座,以全网服务为目标,持续探索下一代T比特级全光网、反谐振空芯光纤、算网一体核心技术,构建跨层化、端到端的新一代AI Native技术体系,通过全光运力与毫秒用算能力,为智能社会建设及算力普惠提供关键支撑,助力AI与网络深度融合发展。