写文献综述的人,多半都有过这样的体验:检索与下载耗去了大半时间,真正坐到文档前,反倒迟迟下不了笔。问题通常不出在文字功夫上,而是心里少了一张“地图”――哪些文献应当进入综述范围、它们之间是承接还是分歧、关键术语在同一学科语境下口径是否一致、最后写下的结论能不能与所引文献一一对上。
国光量子近期推出的科研文献搜集与综述撰写复合应用,正是围绕这些痛点,把“检索―整理―撰稿―校订”拆解为一套可执行、可检查的分步流程,并在界面上实时呈现整体进度,让用户清楚看到自己当前所处的阶段以及已经沉淀下来的中间结果。
文献综述写不动,时间都去哪了?
一篇综述能不能立得住,关键在于“证据池”够不够扎实:覆盖面是否充分,噪声是否可控,重要分支是否被遗漏。实际检索中,同一主题在不同数据库与预印本平台上的表述往往并不一致;如果只靠寥寥几个关键词,常会陷入两难――要么结果过多、筛选成本居高不下,要么策略过窄、错过真正具有代表性的工作。
证据池确定之后,紧接着是知识层面的整理。综述写作必须交代清楚文献之间的关系:技术发展的脉络、方法上的差异、实验条件与结论的对应关系、不同结论背后可能依赖的模型假设。如果缺少结构化的阅读笔记、术语对照与引用关系梳理,写作过程便容易反复停顿――并非找不到词,而是不敢落笔,因为难以快速确认自己的表述是否与所依据的文献相符。
更不必说,文献综述本身就是一项长周期任务,从检索、阅读、笔记到提纲、初稿、多轮修改,环节繁多。若缺少清晰的阶段划分与可交接的中间产物,独立写作时容易在各环节之间来回折返;放到团队协作里,则更容易出现口径不一、重复劳动等问题。
AI总瞎编,通用大模型不好使了?
大语言模型在科研写作辅助上已经相当普及,无论是解释摘要要点、改写句式,还是生成提纲草案,都能为作者节省可观的时间。然而,若把目标定为“在单次对话中直接产出一篇可提交的综述”,恐怕就需要格外审慎。
通用对话形态的大模型在缺乏明确约束时,往往会弱化甚至省略检索与筛选的过程,使读者难以判断结论究竟基于哪些文献、又遵循了怎样的取舍标准。即便是同一概念或同一类实验条件,不同论文的表述也常有差异;模型在生成文本时若对来源信息整合得过于“平滑”,便容易出现术语口径漂移、与原文不完全一致的情况。这些问题在短文本问答中或许并不显眼,可一旦放进综述这种长文本、强引用的场景,人工核对的成本会陡然上升。
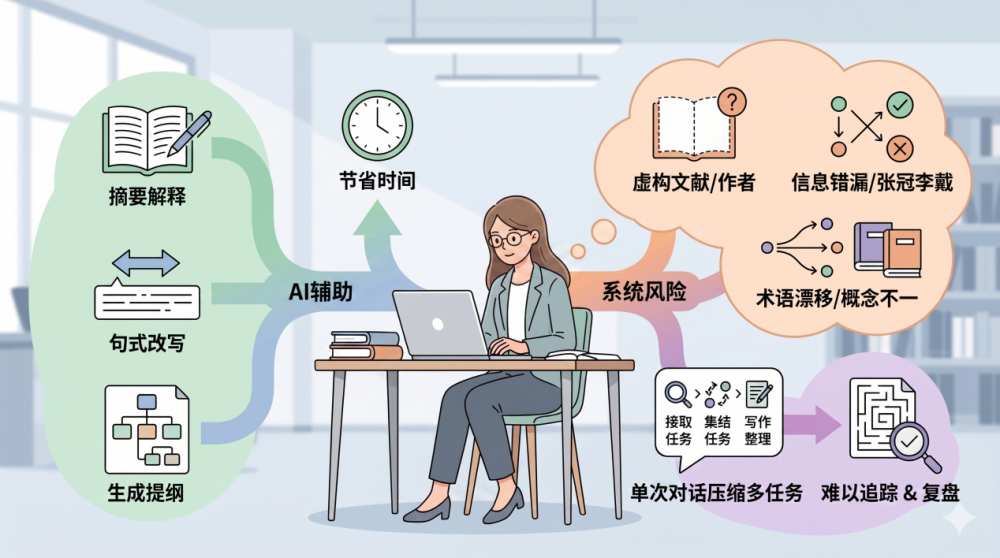
业界通常将这种“语法通顺、语气自信,结论却与可核对事实不一致”的现象称作“幻觉”(hallucination)。典型表现包括:虚构不存在的论文或作者,把不同文献的结论张冠李戴,给出看似具体却无法溯源的实验数据与版本信息,或是在没有依据时补出一段“听起来合理实则错误”的细节。其本质并非“故意造假”,而是概率性语言生成在缺少外部约束与核验机制时的系统性风险。一旦置于综述写作的语境,它直接牵涉的是学术诚信与可复核性,仅凭“读起来像那么回事”,不足以判断文本是否堪用。
再者,综述写作往往由多个相对独立的子任务串联而成:扩展检索、去重与聚类、引用网络与主题结构的把握、分篇提要、术语表维护、提纲编排、初稿撰写以及多轮校订。如果将所有环节压进一次问答,作者既难以追踪每一步的输入输出,也不便在审稿或团队讨论中复盘修订。因此,把长流程切开、让每一阶段都有明确产出,并保留可回溯的中间材料,反而是更稳妥的做法。
国光量子的新思路:分阶段、可追溯、可校订
国光量子将上述判断落实为一套复合应用:系统层面采用多智能体分工与可编排的工作流,把长任务拆解为顺序推进的步骤;交互层面则让用户随时看到进度变化,同步获得各阶段的结果摘要,而不是只在终点收到一份长文。
针对前文谈到的幻觉风险,这套流程并不试图宣称“模型从此不再出错”,而是借助工程化手段,把生成内容尽可能约束在可追溯的证据链之内:先固定文献集合与分篇提要,再让模型在既定材料上组织语言;把“可能编造”的空间压缩为“在已给出的来源范围内进行重述与归纳”,并在校订环节对关键事实与术语一致性进行二次核对。换言之,缓解幻觉的关键在于降低不可核验的自由度,而非用一次长回答把不确定性掩盖过去。
检索阶段强调分步建立文献集合,而不是依赖单次黑箱输出。流程上通常会先覆盖最近一段时间内发表的相关工作,把握研究前沿;再补充按关注度或相关性排序的文献,纳入讨论度较高的代表作;最后沿着候选文献的参考文献链向外扩展,补齐关键经典与重要分支。这样一来,文献集合的形成过程更加透明,也更容易回答“为什么这些论文应当进入综述范围”。
整理阶段强调先完成结构化材料,再进入大段撰写。在落笔之前,系统会引导生成或呈现与写作直接相关的中间结果,例如对候选文献的分组与聚类、引用关系概览、分篇提要句、术语与实体对照、主题发展时间线以及典型应用场景梳理。这些材料的直接作用,是帮助作者在动笔前对齐概念口径、明确各段落准备引用的事实来源,尽量避免凭印象写作带来的表述不一致。
撰稿与校订阶段则把初稿视为可修订版本,而非终稿。在结构化材料之上生成综述初稿后,系统仍保留一道审查与校订环节,用于核对术语与模型假设的前后一致性,并对科研写作中那些容易被忽略、却又至关重要的边界条件――例如有限规模与渐近结论的区别、实验条件与理论模型的对应关系――给出补充说明或修改提示。必要时,还会输出进一步深化阅读或补充论证的建议,便于作者规划下一版工作。
在交互组织上,对话区域与文献管理区域彼此协同:对话侧负责说明流程意图与阶段结论,文献侧用于管理书目、查看补充信息与引用提示,免去用户在多个应用窗口之间频繁切换所带来的注意力损耗。
下面是我们目前已经实现的、以量子密钥分发(Quantum Key Distribution,QKD)相关文献脉络作为示范主题的一套文献综述撰写演示流程,用以完整展示从检索到综述初稿的整条链路。需要补充说明的是,示范本身的意义在于呈现方法与交互形态,并不等同于“对任意主题都能在不加配置的情况下达到同等深度”的自动化承诺。不同学科在检索源、评价指标与写作规范上客观存在差异,实际使用中仍应以人工判断与行业要求为准。

哪些场景更适合?
从使用动机来看,与产品设计目标较为契合的场景大致有以下几类,但远不止于此。
在学位论文与课题开题阶段,作者往往需要在有限时间内建立对子领域的系统认识,并形成一份可继续修改的综述骨架与阅读清单,以便后续逐步嵌入自身的研究贡献与创新表述。分阶段检索与结构化中间材料,恰好把“先读后写”拆成一系列可执行的小目标,缓解一上来就要面对空白文档的压力。
审稿意见或项目评审常会要求补充近年文献,或覆盖某一类方法的代表性工作。此时作者需要在短时间内重建或扩展候选文献集合,并能够说明“为何补充这些文献”。可追溯的建池过程与分组提要,远比单纯追加下载文件更便于写进答复信或说明材料。
交叉学科研究或转入新方向时,作者通常要同时理解多条技术路线及其常用术语。若缺少对照表与引用关系概览,便容易遭遇“同名异义”或“不同文献对同一对象使用不同名称”等阅读障碍。先把术语与实体关系统一梳理,再进入写作,往往能显著减少后期的大规模返工。
科研团队内部的文献综述与资料整理也常涉及分工。如果各成员使用的笔记格式与筛选标准不一致,合并阶段的成本必然抬升。统一的工作流与共享的中间产物,有利于按职责拆分任务(例如分别完善某类提要或某一组术语),再在共同材料的基础上合并撰稿与审校,从而减少重复沟通与口径冲突。
最后仍需重申:工具的作用,是降低重复性劳动与组织成本,而非替代作者的学术判断。是否采纳某篇文献、如何评价不同结论的可靠性、综述最终采取何种立场,仍须由具备相应专业背景的研究者亲自决定。

结语
文献综述的价值,归根到底在于读者能否凭借作者的文字回溯到原始文献,并理解不同工作之间的关系与边界。深度检索解决的是“证据池能否站得住”的问题,多轮校订解决的是“表述能否与证据相符”的问题;二者叠加,也是在系统层面降低幻觉型错误进入终稿的概率。国光量子希望通过分阶段流程与可检查的中间产物,把这两件事,从一项几乎完全依赖个人经验的劳作,转变为可以讨论、可以迭代、可以团队协作完成的工作方式。