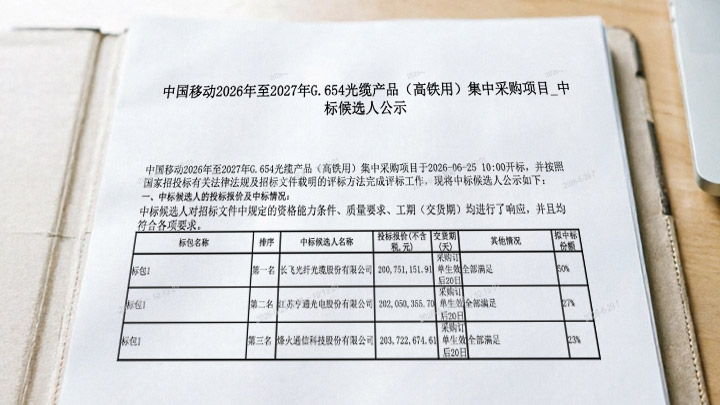
12��13�գ�“2026�й���ͨԺ��ȹ۲챨���”�ڱ����ٰ졣�й���Ϣͨ���о�Ժ���ܹ���ʦ��־Զ����������������������۵�ͼ��⡣

������������ǰ���������Ѿ�ȡ����֪�������������ܵ�˫��ͻ�ƣ���ģ��·�ߡ����ݷ�ʽ�Լ���ѻ�������̬��δ���ͣ����ģ����Դ������ڽΣ���δ���������ڳ�������������ݻ��С�
��������ȡ�ý���ͻ��
�����ע������Ľ�������
��־Զ��ϸ�����˾������ܵ�ǰʵ�ʽ�չ����Ҫ�ص��ע�����ݡ�����ʾ����ǰ�������ܵ�ȷȡ���˽���ͻ�ơ�һ���棬�����˵�“��֪����”ʵ������Ծ������“����”����������ģ��ʹ�������ܹ���ɴ�ͳ���������Դ����ĸ������߱�“�ɸ�֪����˼�����ɽ���”��������������һ���棬“��������”����ͻ�ƣ�����ǿ��ѧϰ�����λ������ڸ��ӵ������ߡ����Ѷ��赸�ȶ�̬�����ϱ�����������������ģ��ѧϰ���ģ�ͷ�ʽ����֫��������������ǿ������ִ���лƹϡ���ˮ�����·��Ⱦ�ϸ������
“Ȼ�������ܼ���ͻ�Ʋ��ϣ��������ܵĴ��ģ����Դ������ڽ�”�� ��־Զָ����“��ǰ��ҵ�������������Ľ������⡣”
������ԣ�һ��ģ��·��֮������ģ�ͷ�ʽ�Ƿ������ڻ����ˣ���Ȼ��ģ�������ԡ�ͼ����Ƶ����ȡ�þ�ɹ�����“ͬ���ķ�ʽ�ܷ�ֱ��Ǩ�Ƶ������˿���”��δ��֤����ҵ������̽������;����
��������ѵ����ʽ֮�����������ݲ��ǻ��������������Ĺؼ���������Ȼ�����ƻ���������Ծ���ĺ���ƿ����Ŀǰ������ģ����Ҫ�����������ݣ�������ݣ�������ߵ��ɼ�����ģ���ޣ��ϳ�/�������ݣ���ģ�ɱ��ͣ��������������һ�����в�ࣻ�����һ�ӽ���Ƶ���ݣ���Ȼ���ḻ����������ע��ӳ�������ս����ǰ�����۱��������������Ƿ���� NLP��CV һ����ѭ Scaling Law——��“��������һ��������ǿ����”����ˣ����ݷ�ʽ���ڿ����ݻ���������ݡ���ģ̬���ݡ�����ģ���������ݵȷ������̽���С�
������̬·��֮�������λ������Ƿ���“������”���������ܵ���س��ֳ�������ϵ���� ���μ����ɣ�Tesla��Figure AI �ȣ�����Щ��ҵ���ȫ����·�ߣ�ԭ���������������������������л����빤����ϵ��������̬������ѧϰ���ද���������������ݣ����ڿ��߱����ͨ���ԡ���˹���� Figure AI ��˳���Ͷ�������Դ����ͼ����“ͨ���Ͷ�������”���� �����ɣ�����������ҵ�������ڽ���ӿ�ֳ����“��-��ʽ���ϻ�����”�����ص��ǣ���ʽ���̸��ɿ����ɱ����͡�������������ɿ���ǿ�����ʺϼ��ɵ���ҵ����������ء�����·����ǿ��“���̿������”��ּ���ڶ������γɿɹ�ģ������ҵӦ�á�
�� VLA ��������������ģ��
������Ϊ���������˴�ģ����������Ҫ·��
����־Զ���ܣ�Ŀǰ�����ô�ģ�����������˵ķ��������ѳ�Ϊҵ�繲ʶ���������Ч�ؽ���ģ��Ӧ���ڻ�����ϵͳ���Դ��ڶ�������·������ҵҲ�ڳ���̽���С�
��һ��·���Dz��ô�����ģ�ͣ�LLM��������ָ�������������������ֽ⣬���Ǹ�������˸߲����ܵĹؼ��������ȸ�� SayCan �����ڴ����Թ������ڶ���·������ LLM �Ļ����������Ӿ���ʹģ�;߱��������Ӿ���ģ̬�ں�������ͨ���Ӿ�����ģ�ͣ�VLM�����л����˿��ơ������Ӿ���Ϣ��ģ�Ͳ����ܷ��������Ŀռ��ϵ���������ԣ�Ҳ�ܸ���֧�Ÿ߲�����滮���ȸ�� PaLM-E չʾ�˿�ģ̬�����ڻ����˿����е�DZ����������·������ VLM �Ļ����Ͻ�һ�����붯�������������γ��Ӿ�-����-����ģ�ͣ�VLA��������ģ�����Ӿ�ͼ�������ָ��Ϊ���룬ֱ����������˿���ָ�VLA ·���� 2024 ��������ܵ��߶ȹ�ע�����ҳ�����ģ�ͼܹ���ģ����ƺͶ������ɷ�ʽ�ϲ����Ż������������� Figure AI��PI���Լ����ڵ���Ԫ������ͨ�õȾ��۽�����һ����
��־Զǿ����Ŀǰ������ VLA ģ�Ͳ��� MoE �ܹ����� VLM ��Ϊ�Ǹ����磬�����㳣ʹ���Իع�Ԥ�⡢��ɢģ�ͻ���ƥ������ɷ�ʽ��ͬʱ���� VLM �붯��Ԥ��֮��ͨ������������������Ϣ���ݣ��Լ�˸�������������ʵʱ��������VLA �ڸ��ӡ��ಽ�衢������������չʾ��һ����Ӧ�ԡ�“Ȼ��������Ҳ�۲쵽������ VLA �ڽṹ�ϲ����ݽ�����ʵ�����Ч����δ�ﵽԤ�ڡ�ԭ����������������и߶ȶ������벻ȷ���ԣ�����ǰ�ɻ�ȡ�Ļ����������������ޡ����dz������㣬ʹ�� VLA ���Գ��ѧϰ����������ʵ�����С�”
չ��δ������ VLA �Ļ��������� ����ģ�ͣ�World Model�����������������������⡢Ԥ��������������������Ϊ��һ�����������˴�ģ����������Ҫ��չ·����
�������úϳ����ݺ���Ƶ����
���������ģ��ѵ������
“�����˵����������Ȼ������ߣ����˹��ɼ��ijɱ����ߣ���������������ϡȱ��ԶԶ������ģ�͵�ѵ��������ˣ�ҵ�翪ʼԽ��Խ���Ӻϳ����ݺ���Ƶ���ݵ����á�” ��־Զָ����
һ���棬ҵ�翪ʼ���û������ѵ��ģʽ�������úϳ����ݻ���Ƶ���ݽ���ģ��Ԥѵ��������������ݽ����������磬����ͨ��ʹ�� 10 ��֡�ϳ��������ץȡģ�͵�Ԥѵ����Ӣΰ�� GROOT N1 ģ���У��ϳɡ���Ƶ��������ݷֱ�ռ 25%��31% �� 44%��“���Ƿ��֣����������ķ��������ռ��ͨ����80%~99%�������ĸ��������ڻ�������������������Ч�����ҵ���������Դ���֤��”
��һ���棬����������ʹ�������һ�ӽ��������Ƶ���ݳ�Ϊ�ƽ�����ƿ����һ����Ҫ�����������������ò���Ա���ͷ��ʽ�����豸���ڲ�Ӱ���ճ�������ǰ���¼�¼��������̣�Ϊģ��ѵ���ṩ������������ʾ�����ݡ�6 �·�����Ϣ�ƣ���˹�˽������Զ���ʻ“ȫ��Ƶѧϰ”��·�ߣ�δ����ѵ������Ҫ�������������һ�ӽǵ���Ƶ���ݡ�Figure AIҲ��9�·ݷ�����Go-Big��Ŀ��Ŀ����ǹ���ȫ����������������ƵԤѵ�����ݼ��������廪��ѧ����ƽ�ߡ���Ԫ�����˵�Ҳ�������·�ߵ�̽����