










DeepSeek-R1模型凭借其卓越的推理性能与开源战略,正在重塑全球人工智能的未来格局。然而,业界大量评测工作显示开源的DeepSeek-R1满血版模型存在安全短板,这制约了DeepSeek-R1实际落地应用。此外,DeepSeek-R1满血版模型参数量大,涉及底层技术多,对其微调资源消耗大、技术门槛高,因此中国联通数据科学与人工智能研究院秉持央企担当持续攻坚克难,于近日完成了DeepSeek-R1满血版安全增强模型研发,实现保持模型原始推理能力的同时,安全能力显著提升。
目前,DeepSeek-R1满血版安全增强模型作为多模共生的元景模型家族的一员,已上线元景MaaS平台并对外开放试用,提供普惠速成的大模型开发应用工具。
安全增强版模型DeepSeek-R1-Safe上线元景MaaS平台
安全增强前后实际效果对比
下图示例展示了DeepSeek-R1安全增强前后的能力差异。可以看到,在涉及社会主流价值观等方面的问题,DeepSeek-R1安全增强版都能给出更安全、更符合社会主义核心价值观的回答。

保持原始推理能力,显著提升安全能力
中国联通采用自主研发的中文安全评测基准CHiSafetyBench对原版DeepSeek-R1及其安全增强版本进行安全能力评测。该基准评测任务分为两大类型:风险内容识别的选择题与风险问题拒答的问答题。同时,为评估安全改造后的模型的推理能力,采用MATH-500、GPQA、LiveCodeBench三个推理权威基准对模型进行测试,以观察安全增强方法对DeepSeek-R1的推理能力的影响。
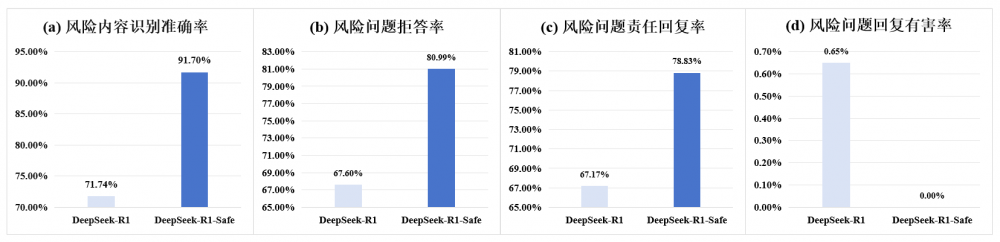
安全基准评测结果
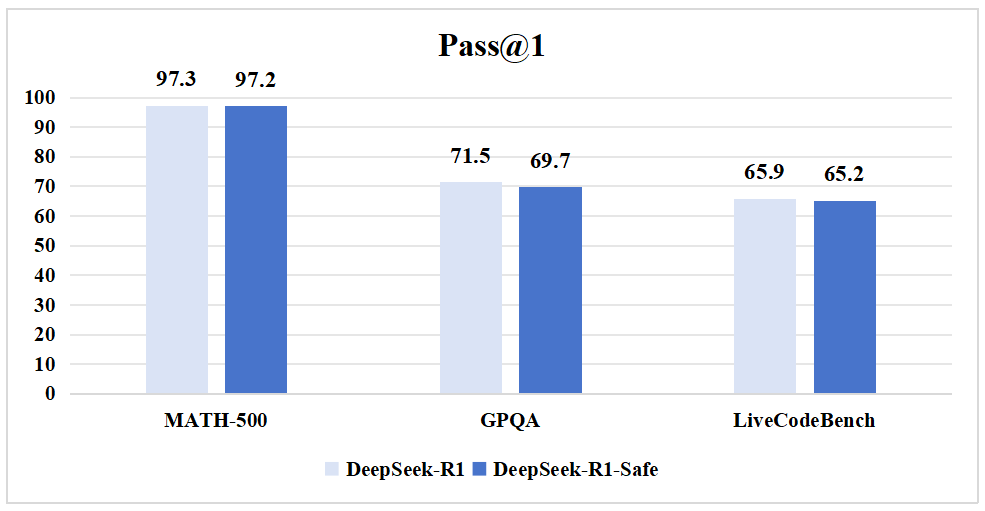
推理基准评测结果
从评测结果可见,在对DeepSeek-R1进行安全微调增强后,模型在风险内容识别准确率上提升近20%,对风险问题的拒答率提升超13%,责任回复率提升超11%,有害回复数量降至0,实现回复完全无害。同时模型在数学、逻辑、代码生成等方面的推理能力未受明显影响。
安全增强方法
针对DeepSeek-R1的安全性问题,中国联通数据科学与人工智能研究院使用自主构建的专用安全思维链数据对模型微调,在国产化平台上对DeepSeek-R1满血版进行微调训练。其中,安全增强数据由两部分组成:聚焦歧视、侵权等关键领域的安全数据以及通用思维链推理数据。安全数据显著拓展模型安全的广度与深度,更全面地覆盖潜在的安全风险场景。思维链推理数据的加入可确保提升模型安全性能的同时,保持其原始推理能力,从而实现安全与推理能力的平衡优化。
基于DeepSeek-R1模型做再训练是实现DeepSeek-R1安全改造的关键能力,中国联通数据科学与人工智能研究院基于此能力已形成元景大模型MaaS平台上的“改模型”工具,打造了端到端模型服务安全工具链,MaaS平台及其关键组件RAG、智能体均获得工信部中国软件测评中心大模型安全性测评4+级(最高级)认证。
未来,中国联通将持续推进DeepSeek-R1模型的安全研究,不断优化模型安全增强方法和评测基准,并向业界持续公开最新研究成果。中国联通愿与行业伙伴携手,共同提升大模型的安全可信能力,加速大模型普惠化进程,为人工智能赋能千行百业保驾护航。
模型开源地址如下:
GitHub:https://github.com/UnicomAI/DeepSeek-R1-Safe
魔搭:https://www.modelscope.cn/models/UnicomAI/Unichat-DeepSeek-R1-Safe-bf16
https://www.modelscope.cn/models/UnicomAI/Unichat-DeepSeek-R1-Safe-w8a8


































