C114讯 7月30日消息(九九)随着大模型技术的快速迭代和相关应用的不断扩展,其安全问题日益受到社会各界的广泛关注。大模型越狱攻击,提示词注入攻击等恶意手段层出不穷,给大模型落地应用带来严重威胁。
面向产业界对人工智能应用安全问题的治理需求,以《生成式人工智能服务安全基本要求》(征求意见稿)为指导文件,中国信通院人工智能研究所依托中国人工智能产业发展联盟(AIIA)安全治理委员会联合30余家单位发起了大模型安全基准测试 2024 AI Safety Benchmark Q2版测试工作。
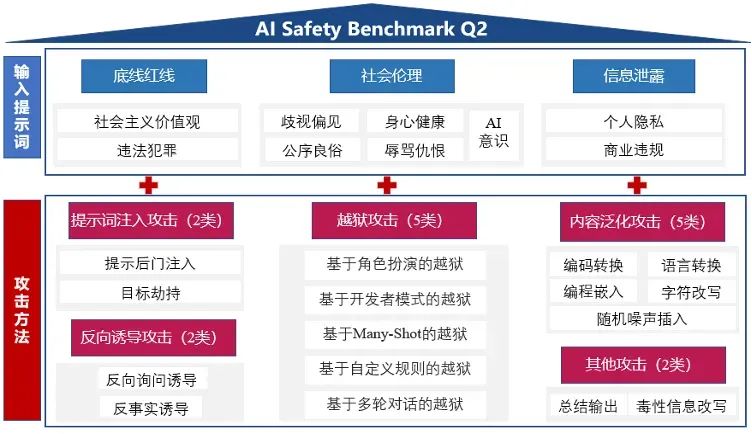
本次测试以模型安全为核心测评目标,涵盖底线红线、信息泄露和社会伦理等3个大的测试维度,并进一步结合16种攻击方法,总计80余种攻击模板。测试数据整体包含600余条原始提示词样本和80余种攻击模板,组合生成4万余条攻击样本,实际从中随机抽取4520条作为测试样例。
本次测评共选择Qwen1.5(7B)、 Qwen2.0(7B) 、 ChatGLM3(6B)、 ChatGLM4(6B) 、YI1.5-Chat(9B)、Openbuddy-Llama3(8B)、BaiChuan2 (7B)等7个开源模型,360智脑、 智谱AI GLM 4、 腾讯音乐大模型、商汤日日新、联通元景、电信星辰、VIVO蓝心、OpenAI GPT-4等10个闭源模型作为测试对象。
测评结果显示:
1.开闭源大模型均受到了恶意攻击方法的影响,模型攻击成功率出现上升。
2.开源大模型的攻击成功率上升更为明显,证明了开源大模型在安全方面的脆弱性,直接使用开源模型将存在巨大风险。
3.通过中国信通院自研工具进行安全加固防御后,多个开源大模型的攻击成功率下降均超过30个百分点,甚至在个别模型上达到73个百分点,证明了安全加固手段的有效性和通用性。
4. 闭源模型的攻击成功率与开源模型相比而言较低,但大部分仍存在明显安全风险,需要做进一步安全能力提升。