










大语言模型(LLM)固有的复杂性使得控制或引导其输出成为一个相当大的技术挑战。2023年12月,美国安全与新兴技术中心(CSET)发布报告《控制大语言模型的输出:初级指南》(Controlling Large Language Model Outputs:A Primer),介绍了LLM潜在的有害输出以及目前开发者用于控制LLM输出的主要技术。可以看出,LLM可控性目前尚无完美解。在实践中,LLM输出控制的各种技术需要相互结合使用,才能最大限度地发挥其作用。
为什么要控制大语言模型的输出?
语言模型本质上是复杂的概率计算机器。它们建立语言token(单词、短语、单词的组成部分,甚至标点符号和语法符号)之间的关系,并计算每个token在响应给定提示词时的出现概率。模型反复选择最有可能出现的token,直到输出完成。这意味着语言模型对事实性或真实性并无基本理解,也并非从任何单一来源检索信息。它们更像是“即兴创作机器”:擅长复制模式,但没有内置方法来验证其输出是否有用、正确或有害。
以下三类潜在的有害输出,是LLM输出控制的主要原因:
1. 不准确信息(incorrect information)
一些普通用户不了解模型的局限性并且不恰当地引用,认为它们提供了事实信息(AI研究人员称之为“过度依赖”)。例如,依赖模型获取健康信息的用户如果得到错误建议,可能会将自己置于危险之中;依赖模型获取政治信息的用户如果收到错误信息,可能会毫无理由地对候选人失去信任。随着人们越来越频繁地使用LLM,与过度依赖相关的风险可能会越来越大。
2.偏见或有毒输出(biased or toxic outputs)
并非明显虚假的内容才会造成伤害。当LLM产生有偏见(例如关于种族、性别、宗教或其他类别)或有害的文本时,就会引发一系列问题。有研究已经测试并发现了与政治意识形态、宗教、性别等有关的偏见证据。另一项研究将LLM中的偏见追溯到训练数据,并指出基于某些关键词从训练数据中排除的内容会不成比例地删除关于各种少数群体成员的文本。
3.恶意使用(outputs resulting from malicious use)
不良行为者有可能故意使用LLM进行“恶意使用”。最坏情况之一是不良行为者利用LLM学习如何制造炸弹或生物武器,不同类型的恶意行为还包括使用LLM来促进黑客攻击、诈骗或生成虚假信息文章等等。
控制大语言模型的输出的四种技术
LLM的开发分为预训练、微调、部署三个阶段,相关的语言模型控制技术可运用于不同阶段以引导其输出。
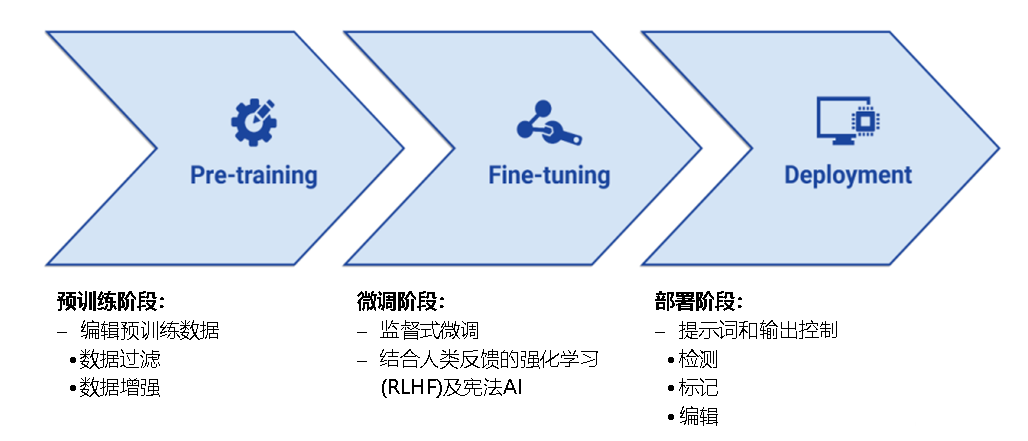
图1 LLM开发的三个阶段及相关的语言模型控制技术
(来源:Controlling Large Language Model Outputs:A Primer,CSET,2023.12)
1. 编辑预训练数据(Editing Pre-training Data)
语言模型的预测能力来自于其训练文本中的相关性,因此对LLM的一个常见误解是通过操纵或编辑其训练数据,可以轻易地引导其输出。然而,现实世界中的预训练要复杂得多。考虑到这些模型的预训练数据量之大,要预测训练数据的变化将如何影响其性能或输出某些类型内容的倾向是极其困难的。
虽然训练数据操纵在理论上是控制模型行为的强大机制,但它并非预防许多类型有害输出的灵丹妙药,尤其是当意义和危害依赖于上下文的时候。尽管内容过滤器和数据源等因素最终会对完全训练模型的行为产生重大影响,但研究人员尚未完全理解应该如何操纵数据,才能在对模型产生有意义影响的同时,最大限度地减少性能损失。在经过精心策划的数据集上预先训练较小的、专业化的语言模型,可能更容易在数据过滤或增强方面取得成功,但LLM开发者可能还需要依靠其他方法来引导他们的模型。
2. 监督式微调(Supervised Fine-Tuning)
模型经过预训练后,开发者可以通过在专门的数据集上进一步训练来继续调整其行为。这一过程被称为监督式微调,是修改语言模型最常见方法之一,通常是为了提高模型在特定领域的性能。模型接触到与特定主题相关的高质量数据越多,就越能以对人类用户有用的方式预测其输出中的下一个token。
在合适的上下文中,如果有合适的数据,监督式微调会非常强大,并且是将模型针对特定领域或用例进行特定调整的最佳方法之一。(这里的“监督”指的是模型被提供了标注数据,因此无需执行对数据中的模式和关联性进行学习的前提步骤。)然而,有效的监督式微调取决于对专业和高质量数据集的访问,而这些数据集并非在所有领域都可获得,或者无法准确地捕捉研究人员试图控制的行为。因此,研究人员希望开发出不依赖专业数据,或者能够以更灵活方式引导LLM行为的替代技术。
3. 人类反馈强化学习(RLHF)及符合“宪法”的AI(Reinforcement Learning with Human Feedback and Constitutional AI)
人类反馈强化学习(RLHF)是一种借助不同的机器学习模型(称为“奖励模型”)对LLM进行微调的技术。该模型在原始LLM的一些文本输出上进行训练,人类标注者根据一些准则或偏好对这些文本输出进行排序。前文所提监督式微调通常用于创建专门的模型,不一定涉及基于任何“对”或“错”的感觉来指导模型;与其不同,RLHF的核心原则是人类偏好应在LLM的行为中发挥作用。“人类反馈”是RLHF的核心组成部分,也是其最大的局限性。只要RLHF需要人力,那么LLM创建者在其模型获得多少人类反馈方面自然会面临限制,因为这些措施的时间和成本都非常高。此外,设计不当的反馈过程可能会导致模型学会如何采取行动以最大限度地获得积极反馈,但实际上却可能无法转化为符合人类用户偏好的输出类型。
符合“宪法”的AI(Constitutional AI,或译“宪法”AI)是AI公司Anthropic开发的一种训练方法,旨在尽可能少地使用人类指导来引导LLM的行为。与RLHF不同,“宪法”AI不依靠人类标签或注释来编码人类偏好;相反地,研究人员提供了一系列指导规则或原则,因此被称为“宪法”,实质上通过另一个模型来评估并修订其输出。尽管“宪法”AI有望成为RLHF的替代品,其依靠人工生成的标签要少得多,但RLHF似乎仍然是在微调阶段指导和引导LLM的行业标准。
4. 提示词和输出控制(Prompt and Output Controls)
即使经过预训练和多轮微调,LLM仍可能输出非期望文本。在将模型整合到面向消费者的产品之前,开发者可以选择在输出前或输出后阶段使用其他技术来控制模型。这些技术通常也被称为“输入过滤器”(应用于输出前阶段)和“输出过滤器”(应用于输出后阶段),通常分为三个步骤:检测、标记和编辑。
在LLM接收到用户输入之前,开发者可以对提示词进行筛选,评估它们是否可能引发有害文本,并向用户显示警告或拒绝信息。这可以产生类似于模型本身拒绝回答某些类型提示词的效果。
一旦LLM对提示词做出了响应,但在向用户显示输出之前,开发者可以进行额外的检查和过滤。与监督式微调一样,这些技术依靠人类标记的数据。微调阶段之后的模型控制通常还与监控或用户举报相结合,通常这涉及自动内容检测或过滤、人工内容审核和用户举报的组合。最后,如果有害或非期望输出通过了所有现有控制,许多LLM界面包含用户反馈机制,使用户可以直接标记单个输出。开发者难以捕捉到每一个可能导致有害输出的提示词或用例,因此需要依靠用户对模型性能提供反馈。
思考与启示
2023年8月起施行的《生成式人工智能服务管理暂行办法》,除了禁止生成违法违规内容,还要求在模型生成和优化等过程中,采取有效措施防止产生民族、信仰、国别、地域、性别、年龄、职业、健康等歧视;并且要采取有效措施,提高生成内容的准确性和可靠性。这些都说明了输出控制的重要性。
1. LLM可控性尚无完美解
可控性是LLM 的重点研究方向之一,但目前学术界并无完美解,正如CSET报告所言,“即使是最前沿的控制措施也不能保证LLM永远不产生非期望输出”。尽管开发者尽了最大努力,非期望输出仍会时有发生。任何以特定方式控制模型的尝试,都可能产生意想不到的后果。在实践中,LLM输出控制的各种技术需要相互结合使用,才能最大限度地发挥其作用。
2. 多方协同推动各环节逐步逼近
一是监管部门和产业界多方协同,遵循包容审慎原则,共同建立可信可控的大模型监管体系。二是从内容和逻辑的准确性、价值观的一致性、决策过程的透明度和可解释性、输出内容的安全合规性等多个维度提升LLM输出结果的可控性。三是构建评测标准生态,推动建立LLM评测体系,以科学有效的评测工具和评测方法,高效评估LLM的生成内容质量。
本文作者


宋杰
战略发展研究所
资深分析师



































