C114讯 6月13日消息(岳明)在Generative AI向Agentic AI的演进浪潮中,要想继续留在“牌桌”上,产品技术创新和产业生态合作同样重要。
作为在Generative AI时代的赢家之一,AMD显然想赢得更大的牌局,但这并非易事,AMD该如何破局?太平洋时间2025年6月12日上午9:30,AMD董事会主席及首席执行官苏姿丰(Lisa Su)博士在Advancing AI大会上给出了自己的答案:领先技术+开放生态+全栈方案!

在领先技术层面,AMD瞄准4000亿美元的AI硬件市场,已经构建起了包括CPU、GPU、DPU、FPGA等在内的完整技术堆栈,而且在快速价值迭代;在开放生态层面,AMD正在加大对ROCm软件生态系统的建设投入,最新版本ROCm 7已经面向生成式AI和高性能计算工作负载日益增长的需求做足准备;在全栈方案层面,AMD正在强化云边端协同的集成 AI 平台愿景,将推出基于行业标准构建的、开放且可扩展的机架级AI基础设施―“Helios”AI机柜。
技术领先:Instinct MI350系列GPU实现35倍推理性能提升
在上午的发布环节,采用台积电的3nm工艺,集成1850亿晶体管的Instinct MI350系列GPU无疑是最大亮点。
作为AMD历史上最为成功的产品之一,Instinct MI350系列GPU采用了CDNA 4架构,在性能、内存容量、带宽,GPU执行单元数量、吞吐性能等方面实现了全面进化,并且通过2.5D和3D先进封装技术实现了晶体管的更高密度集成以及更好的能效表现。

性能方能,Instinct MI350系列GPU支持多种浮点精度数据格式,包括FP8、FP6、FP4、FP16、BF16以及FP64等。相比前代产品,其AI算力得到显著增强,FP16性能达到18.5 PFlops,FP8为37 PFlops,FP6/FP4高达74 PFlops。MI350系列GPU的模型参数处理能力从7140亿激增至4.2万亿,提升近6倍,能够有效满足大语言模型和混合专家模型的训练与推理需求。
内存和带宽容量方面,这是AMD GPU产品区别于友商的强项。在Instinct MI350产品上,这种优势得到了进一步加强,其内存容量达到了288GB HBM3E,最大带宽能力为 8TB/s,无论是训练还是推理,都能获得更好的吞吐量。
对于如此高算力、高密度的AI硬件产品而言,散热和功耗是必须要面对的。Instinct MI350系列GPU可以支持风冷和直接液冷灵活配置,风冷机架中最多可部署64个GPU,液冷机架中最多可部署128个GPU,提供高达2.6 exaFLOPS 的 FP4/FP6 性能。
当然,对于最终用户而言,TCO是个更核心的话题。苏姿丰博士介绍,相比英伟达B200,AMD Instinct MI300X系列GPU每美元可处理的Token数量提升高达40%,相当于在运行大语言模型(LLM)时,单位成本下的计算效率提升40%。

而且在本次峰会上,AMD还剧透了下一代Instinct MI400系列GPU的特性,它将拥有高达40PF和20PF的FP4/FP8算力,并打在432GB HBM4内存,带宽将提升至19.6 TB/s,每个GPU的横向扩展带宽将达到300 GB/s,进一步为AI计算提速。

不仅在算力层面,在网络连接层面,AMD推出了业界首款支持超以太网联盟(UEC)特性的AI智能网卡――AMD Pensando Pollara 400,该AI智能网卡专为加速后端网络应用而设计,实现了400千兆比特每秒(Gbps)的以太网传输速率。
开放生态:开发者至上,全新ROCm 7+开发者云
开发者,开发者,开发者。
从会议现场某位演讲嘉宾的开场白中,我们就能深刻体会到软件和生态的重要性,而这也是AMD最大竞争对手英伟达的护城河。

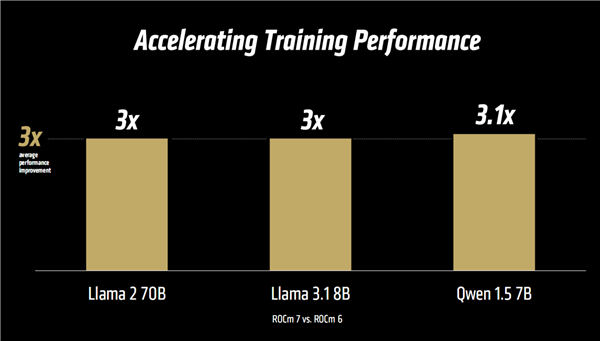
对此,苏姿丰博士给出的答案是ROCm 7和开发者云。AMD对ROCm的愿景是通过一个开放、可扩展且专注于开发者的平台,为所有人解锁创新潜能。据苏姿丰博士介绍,过去一年中,ROCm迅速成熟,并深化了与主流开源社区的集成。如今,ROCm驱动着全球最大型的一些AI平台,支持Llama、DeepSeek等主流模型,特别是在最新的ROCm 7版本中实现了超过 3.5 倍的推理性能提升。
随着AI应用从研究转向企业世纪部署,ROCm也在同步演进。ROCm企业级AI将一套全栈式MLOps 平台推向台前,凭借支持超过 180万个Hugging Face模型的开箱即用体验,以及行业基准测试的引入,ROCm提供用于微调、合规、部署和集成的开箱即用工具,以实现安全、可扩展的AI。“ROCm 不仅是在追赶――它正在引领开放的AI革命”,苏姿丰博士在演讲中强调。
与ROCm 7相伴而来的,还有极具灵活性和可扩展性的AMD开发者云服务。AMD开发者云服务具备零设置环境、支持预安装的Docker容器和出色的灵活性、在Day-0生态的Instinct MI350系列GPU系统支持能力、拥有多元化的可扩展计算选项、为开发者提供免费额度等多重亮点。也就是说,无论是何种应用场景,AMD开发者云都提供了即时开始的工具和灵活性,让开发者在不受限制的环境中释放生产力。
全栈方案:“Helios”AI机架实现“集大成”
随着大模型训练和推理对算力需求的爆炸式增长,传统计算架构已难以支撑AI技术的代际跃迁。
超节点,作为AIDC算力Scale Up的当前最优解,通过内部高速总线互连,能够有效支撑并行计算任务,加速GPU之间的参数交换和数据同步,缩短大模型的训练周期,在性能、成本、组网、运维等方面,能为用户带来巨大优势。

AMD显然也看到了这个趋势。在Advancing AI大会上,AMD宣布正式推出Helios AI机柜基础设施,将包括AMD EPYC“Venice” CPU、Instinct MI400系列GPU和Pensando “Vulcano” AI 智能网卡――与ROCm软件统一整合为一个完全集成的解决方案。AMD的目标非常明确,那就是打造“The World’s Best AI Rack Solution”。
从现场披露的数据来看,Helios AI机架可容纳最多72块MI400系列GPU,总带宽260TB/s,HBM4内存总容量31TB、总带宽1.4PB/s。整机性能,Helios AI 机架可高达 FP8 1.4EFlops ( 140 亿亿次每秒 ) 、FP4 2.9EFlops ( 290 亿亿次每秒 ) 。
正如苏姿丰博士所讲的,AMD是唯一具备全面覆盖数据中心、边缘及终端设备端到端AI能力的供应商,拥有支撑全栈AI所需的硬件矩阵与软件实力。在过去的六年中,AMD EPYC在服务器CPU市场上实现了超过18倍的份额提升,从原来的2%上升到40%(1Q25);我们完全有理由相信,在更加波澜壮阔的AI时代,在“领先技术+开放生态+全栈方案”的加持下,AMD将会迎来新一轮成长。