随着机器学习(Machine Learning)领域越来越多地使用现场可编程门阵列(FPGA)来进行推理(inference)加速,而传统FPGA只支持定点运算的瓶颈越发凸显。Achronix为了解决这一大困境,创新地设计了机器学习处理器(MLP)单元,不仅支持浮点的乘加运算,还可以支持对多种定浮点数格式进行拆分。
MLP全称Machine Learning Processing单元,是由一组至多32个乘法器的阵列,以及一个加法树、累加器、还有四舍五入rounding/饱和saturation/归一化normalize功能块。同时还包括2个缓存,分别是一个BRAM72k和LRAM2k,用于独立或结合乘法器使用。MLP支持定点模式和浮点模式,对应下面图1和图2。
.png)
图1 定点模式下的MLP框图
.png)
图2 浮点模式下的MLP框图
考虑到运算能耗和准确度的折衷,目前机器学习引擎中最常使用的运算格式是FP16和INT8,而Tensor Flow支持的BF16则是通过降低精度,来获得更大数值空间。下面的表1是MLP支持的最大位宽的浮点格式,表2说明了各自的取值范围。
.png)
表1 MLP支持的最大位宽的浮点格式
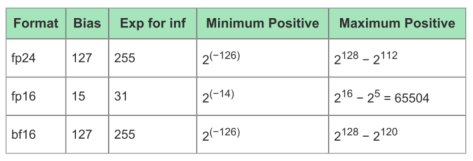
表2 不同运算格式的取值范围
而且这似乎也成为未来的一种趋势。目前已经有不少研究表明,更小位宽的浮点或整型可以在保证正确率的同时,还可以减少大量的计算量。因此,为了顺应这一潮流,MLP还支持将大位宽乘法单元拆分成多个小位宽乘法,包括整数和浮点数。详见下表3。
值得注意的是,这里的bfloat16即Brain Float格式,而block float为块浮点算法,即当应用Block Float16及更低位宽块浮点格式时,指数位宽不变,小数位缩减到了16bit以内,因此浮点加法位宽变小,并且不需要使用浮点乘法单元,而是整数乘法和加法树即可,MLP的架构可以使这些格式下的算力倍增。
表3是Speedster7t系列1500器件所支持的典型格式下的算力对比,可以看到,单片FPGA的浮点算力最高可达到123TOPS。
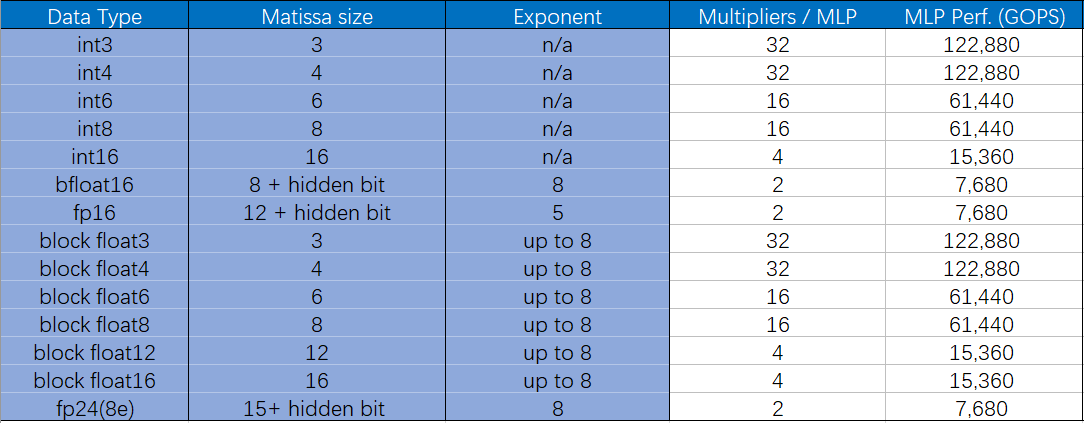
表3 Achronix的Speedster7t系列1500器件支持的典型格式的算力对比
下图3是MLP中FP24/FP16乘加单元的简化结构图,即一个MLP支持FP24/FP16的A*B+C*D,或者A*B,C*D。
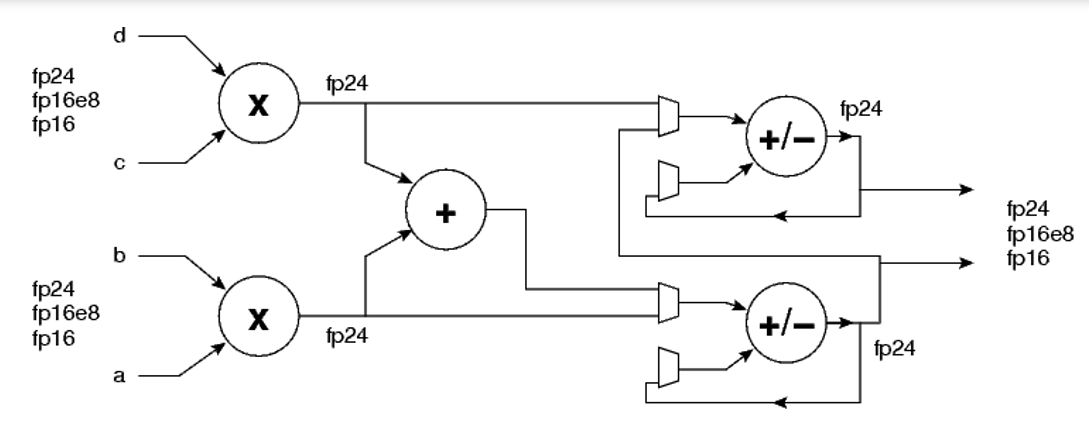
图3 MLP中FP24/FP16乘加单元的简化结构图
而以下的图4则是块浮点乘加单元结构。
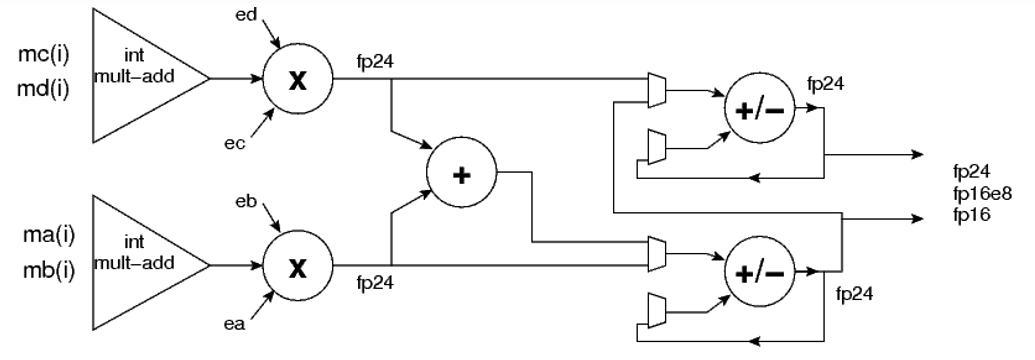
图4 块浮点乘加单元结构
这里考虑浮点数序列块ai=mai·2ea,浮点数序列块bi=mbi·2eb,各序列块内均拥有相同的指数ea和eb。则
.png)
不难看出,乘法单元的个数取决于尾数(即整数)位宽。

表4 MLP中乘法单元的个数与整数位宽的关系
作者:杨宇,Achronix资深现场应用工程师