近日,中国移动研究院撰写的论文“Efficient Automatic Arrangement Algorithm for Computing In Memory Chips Array”被第三十一届国际神经信息处理大会(ICONIP2024)录用。
近年来,人工智能尤其是大模型对算力的需求呈爆炸式增长,而经典的冯·诺依曼架构因存储与计算分离带来的数据搬运时延及能耗成为算力增长的主要瓶颈。存算一体技术在存储原位实现计算功能,可以突破冯·诺依曼架构瓶颈,大幅提升算力和能效水平。但是,由于存算一体芯片涉及架构、器件、材料、算法的全新创新,面临模型编排复杂度高、阵列利用率低下的问题,阻碍存算一体芯片的应用拓展。针对上述问题,论文提出一种面向存算一体芯片的新型多阵列AI模型编排算法,可以大幅提升编排效率和芯片阵列利用率。该成果为面向存算一体芯片的AI模型编排部署提供重要参考,对于推进存算一体芯片的工程化和产业化有重要意义。

图1 论文首页
论文将AI模型不同层权重在存算一体芯片多阵列的优化编排问题转化为面向阵列利用率提升的序列到序列排序问题,创新地提出了一种基于改进指针网络(Pointer Net)的AI模型分层排序算法,采用长短期记忆网络(LSTM)作为指针网络的编码器(Encode)与解码器(Decode),增加了模型序列记忆能力,同时引入注意力机制,提升算法序列预测的准确性。图2为算法网络结构图,输入数据为模型各层权重尺寸与存算阵列尺寸的比例,输出数据为模型该层权重在阵列中的编排顺序。
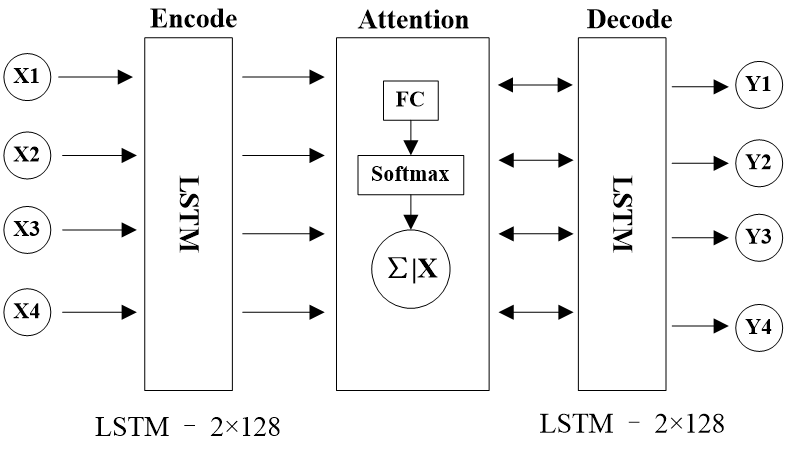
图2. 基于序列到序列指针网络的AI模型分层排序算法结构图
论文采用人工蜂群算法(Artifical Bee Colony,ABC)在ONNX开源模型库搜索匹配不同存算一体芯片阵列特征的网络计算层最优排序,作为标注数据集训练指针网络训练。在模型编排阶段,论文提出的基于序列到序列的模型编排算法计算复杂度由ABC算法O(n3)降为O(n),其中n为AI模型的层数,预测准确率达到ABC算法的96%,在保证准确率的同时大幅降低计算时延。尤其对于层数较多的复杂AI模型,本文方法发挥的优势更为明显,如图3所示,对于100层以上网络,编排效率超过传统ABC算法10倍。
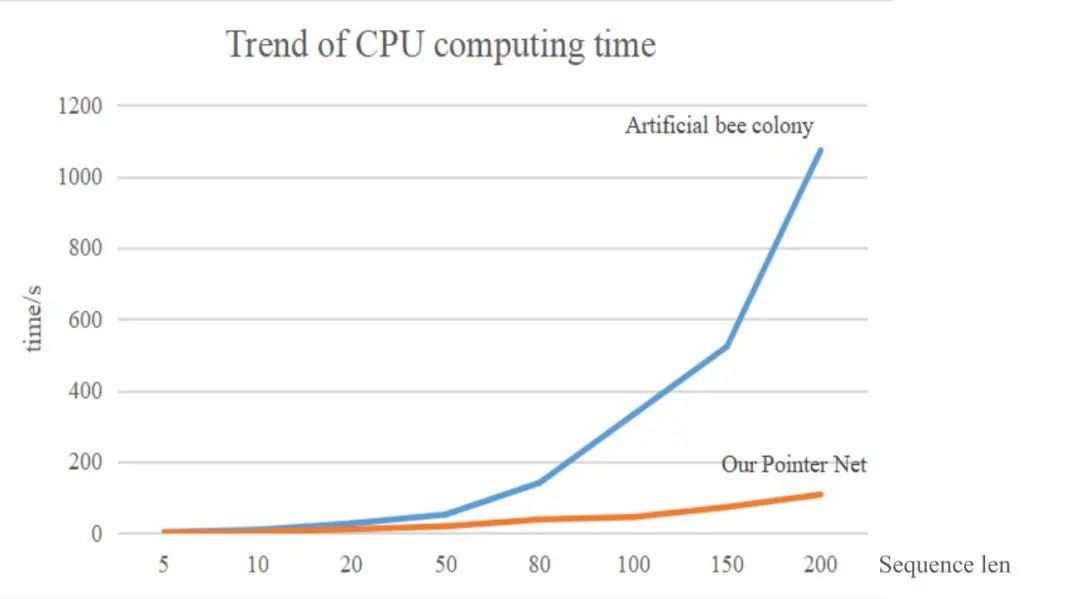
图3. 论文算法跟人工蜂群算法计算时延对比图
最后,基于指针网络输出地分层编排顺序,综合AI算子特征和阵列冗余空间形成算子在阵列的最优编排策略,有效保证芯片阵列占用率。图4是Yolov5s模型在一个2阵列(阵列尺寸1024x512)存算一体芯片上的编排结果,阵列1利用率达94.14%,阵列2达利用率93.97%。


图4. Yolov5s网络模型在存算一体芯片上的编排结果
下一步,中国移动研究院将继续开展存算一体关键技术研究,围绕软件架构、优化算法、场景应用等环节持续发力,推动存算一体技术成熟。