










���գ��й��ƶ��о�Ժд������“Collaborative Training for Compensation of Inference Errors in NOR Flash Computing in memory Chips”���ڶ�ʮ�߽�IEEE���������Эͬ��������ƴ�ᣨCSCWD 2024��¼�ã��й��ƶ��о�Ժר��������ϯ��Ტ�����ķ������ݽ���
�������˹����������Ǵ�ģ�Ͷ�����������ʱ�ըʽ������������ķ�·ŵ�����ܹ���洢����������������ݰ���ʱ�Ӽ��ܺij�Ϊ������������Ҫƿ��������һ�弼���ڴ洢ԭλʵ�ּ��㹦�ܣ�����ͻ�Ʒ�·ŵ�����ܹ�ƿ�������������������Чˮƽ�������ڴ���һ���������ڷ��������ԣ��������ת����������д��������⣬�Ӷ�Ӱ����㾫�ȡ�����������⣬�������һ���������һ��оƬ��AIģ��Эͬѵ���ܹ���ͨ����ģ��ѵ��������ʹ�ô���һ��оƬ������������з���������ģ��Ȩ�أ��Ӷ�����ģ���ڴ���һ��оƬ������³���ԡ��óɹ�Ϊ�������һ��оƬ��ģ��ѵ���ṩ��Ҫ�ο��������ƽ�����һ��оƬ�Ĺ��̻��Ͳ�ҵ������Ҫ���塣
��ѵ���ܹ����棬���������һ���������һ��оƬ������Эͬѵ���ܹ���ͼ1�����������ݼ�������ģ��ѵ����������ģ��Ƭ�ϼ��������֡����Ȱ���оƬ���㾫�ȶ������ѵ�����ݼ�����INT8������Ȼ������������ݼ���CPU/GPU��ѵ����FP32���ȵ�ģ�ͣ��ٽ�ģ�ͽ�������������һ��оƬ�ϲ������������ݼ�����ǰ����㣬������оƬʵ�ʼ���������ֵ����ģ����ʧ����������ģ��Ȩ�أ�����ѵ��������ģ�Ϳ��Լ��������ڴ���һ��оƬ�����������³���ԡ�
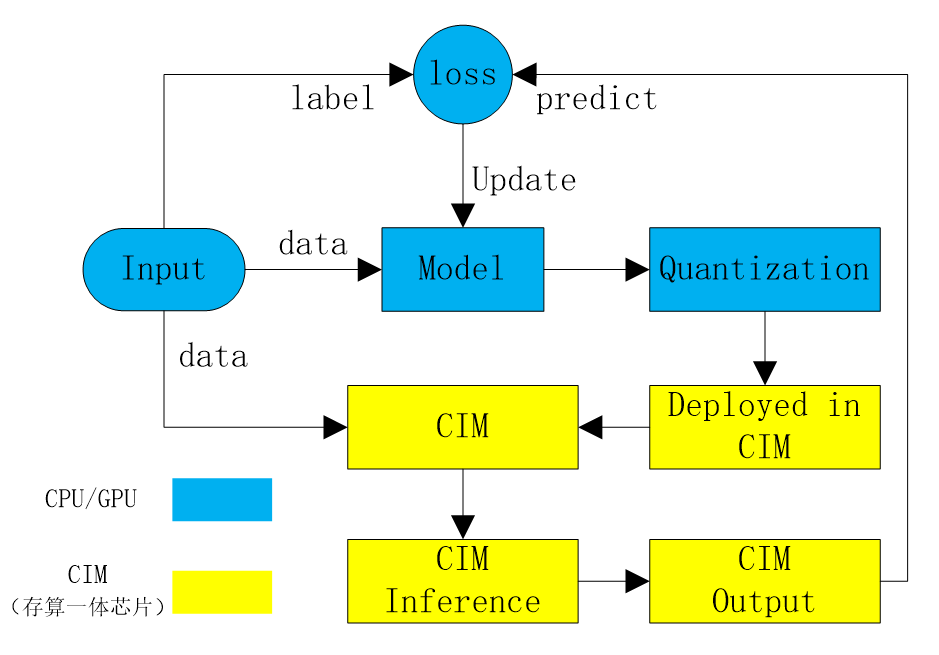
����ͼ1 �������һ��оƬ��AIģ��Эͬѵ���ܹ�
���⣬���������һ�ֻ��ڶԳƶ��������ӵ�Эͬ�������������Խ�оƬ�˵�INT8���㾫�Ⱥ�ѵ��������FP32����ģ����Ч�ں���ͼ2�������оƬ����[-128, 127]�ľ��ȷ�Χ����ģ��ѵ������Ȩ��ʱ��Ȩ������������[-0.125, 0.125]��Χ���Ӷ�����ͳһ��1024Ȩ�ر������ӣ�������ѵ��������������������Ӷ���������������ģ��ѵ�������ٶȡ�
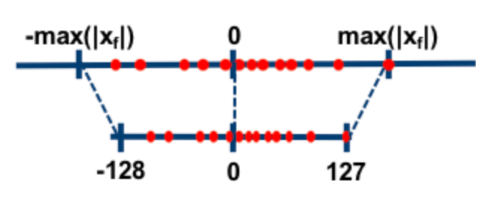
����ͼ2�Գƶ�����������������
��һ�����й��ƶ��о�Ժ��������չ����һ��оƬ���������㷨��Ӧ�õ���ؼ����о����ƽ�����һ���ڶˡ��ߡ��Ƶ�Ӧ�ó����Ĺ㷺Ӧ����ء� 


































