谷歌昨日(1 月 15 日)发布博文,基于 Gemma 3 架构,推出 TranslateGemma 开放翻译模型系列,共有 4B、12B 和 27B 三种参数规模,支持 55 种核心语言及多模态图像翻译,目前已在 Kaggle 和 Hugging Face 开放下载。
性能方面,谷歌团队利用 WMT24++ 基准(包含高、中、低资源语言的 55 种语言)和 MetricX 指标进行了严格测试。
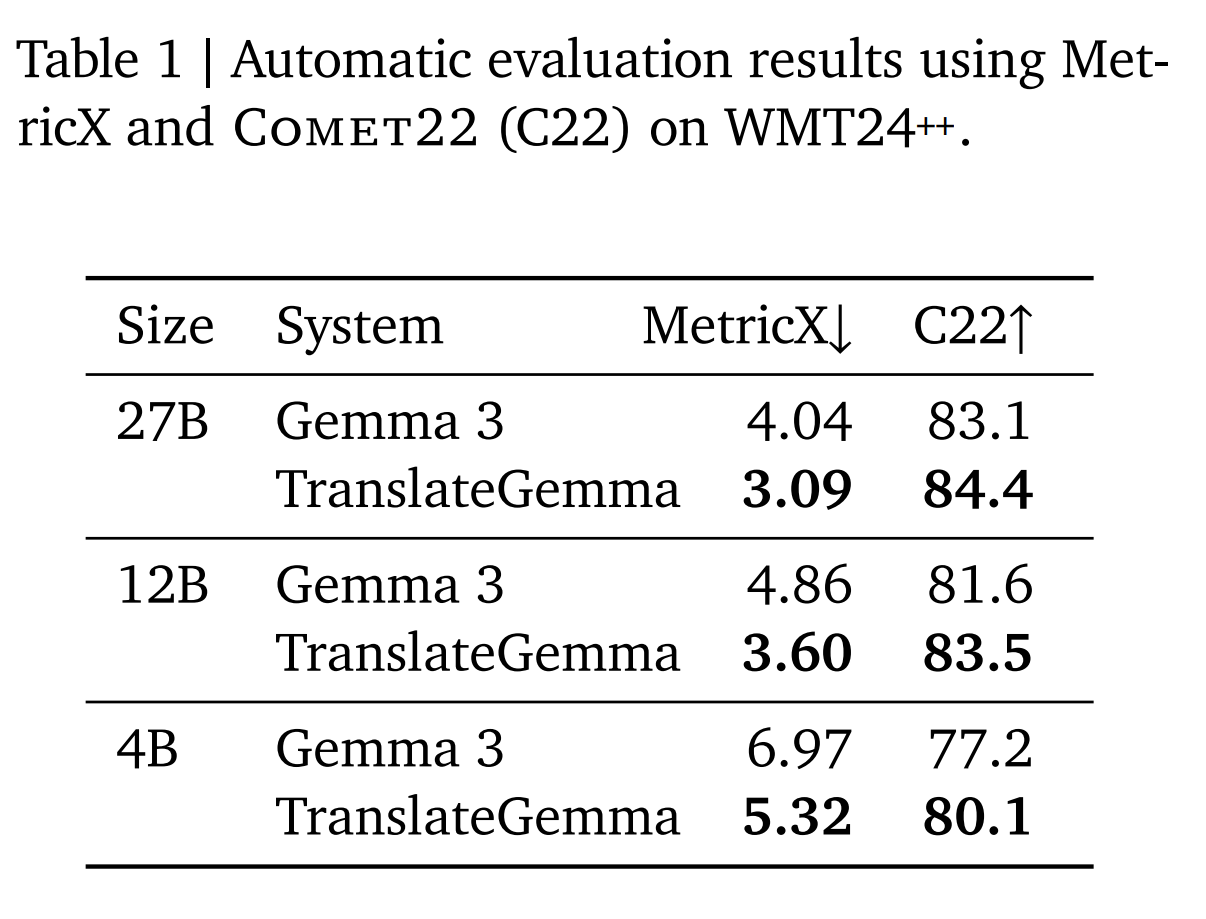
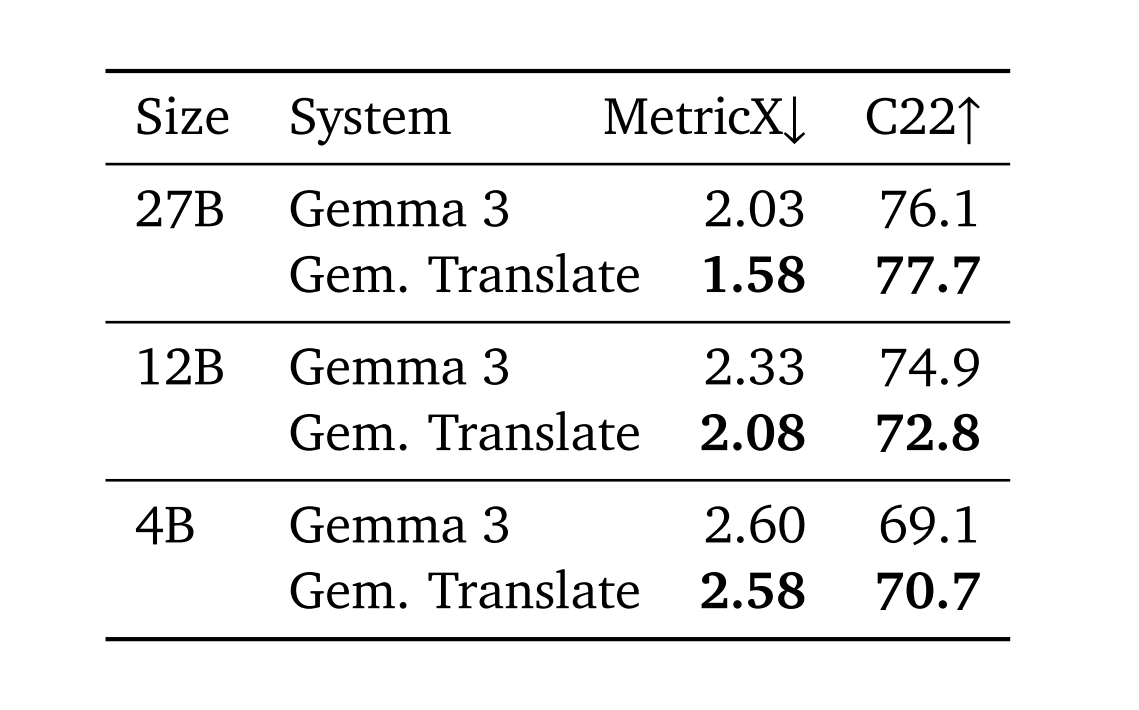
结果显示,TranslateGemma 12B 版本的翻译质量超越了参数量大其两倍的 Gemma 3 27B 基线模型。这意味着开发者仅需消耗一半的算力资源,即可获得更高保真的翻译结果,从而大幅提升吞吐量并降低延迟。

同时,体量最小的 4B 模型也展现出惊人实力,其性能与 12B 基线模型相当,为移动端和边缘计算设备提供了强大的翻译能力。
技术方面,TranslateGemma 的高密度智能源于独特的“两阶段微调”工艺。
首先是监督微调(SFT),Google 利用 Gemini 模型生成的高质量合成数据与人工翻译数据混合,对 Gemma 3 底座进行训练;随后引入强化学习(RL)阶段,通过 MetricX-QE 和 AutoMQM 等先进奖励模型,引导模型生成更符合语境、更自然的译文。
在语言覆盖方面,TranslateGemma 重点优化并验证了 55 种核心语言(涵盖西班牙语、中文、印地语等),并进一步探索训练近 500 种语言,为学术界研究濒危语言提供了坚实基础。
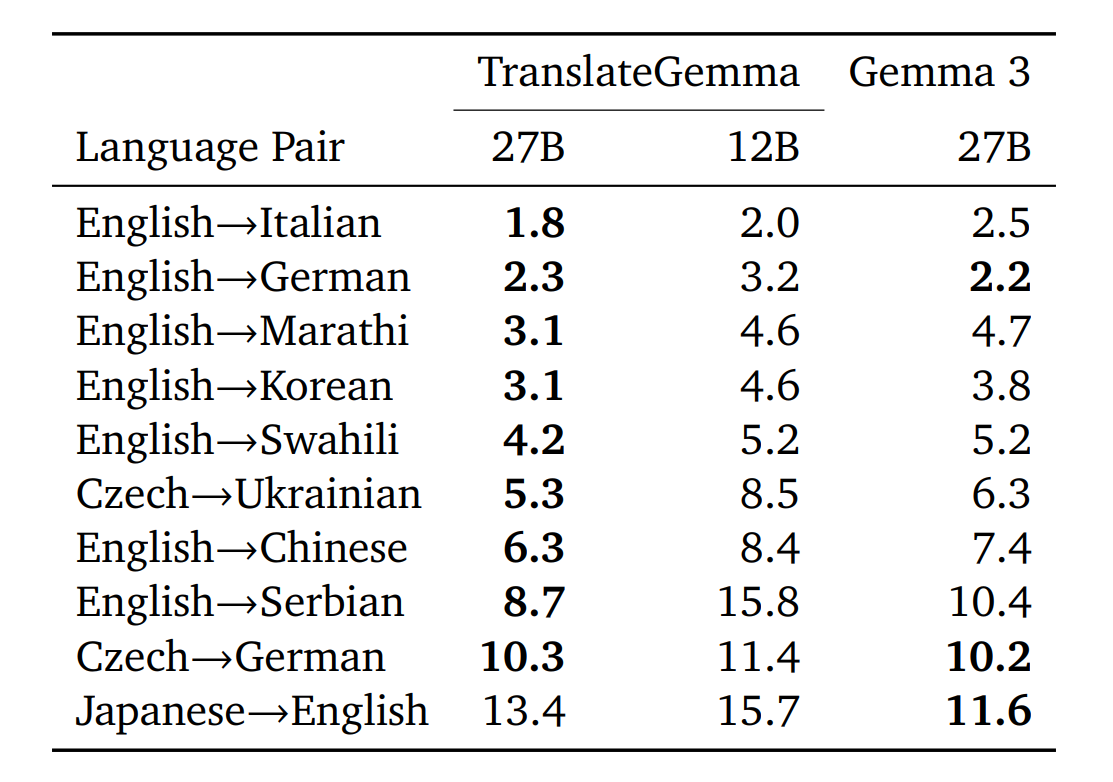

此外,得益于 Gemma 3 的架构优势,新模型完整保留了多模态能力。测试表明,无需额外针对视觉任务进行微调,其在文本翻译上的提升直接增强了图像内文字的翻译效果。

为了适应不同的开发需求,TranslateGemma 的三种尺寸对应了精准的部署场景:
4B 模型专为手机和边缘设备优化,实现端侧高效推理;
12B 模型适配消费级笔记本电脑,让本地开发具备研究级性能;
27B 模型则面向追求极致质量的场景,可运行于单张 H100 GPU 或云端 TPU 上。
所有模型目前均已在 Kaggle、Hugging Face 及 Vertex AI 上线。