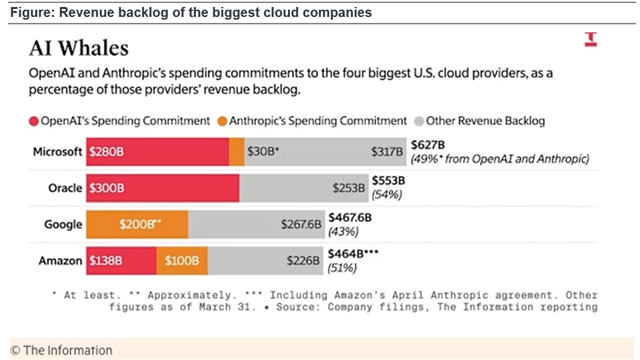
ΑΔάοΆ®“ε«ßΈ Qwen Ά≈Ε”Ήρ»’Θ®5 ‘¬ 26 »’Θ©ΖΔ≤Φ QwenLong-L1-32B ΡΘ–ΆΘ§ «Τδ ΉΗωΆ®Ιΐ«ΩΜ·―ßœΑ―ΒΝΖΒΡ≥ΛΈΡ±Ψ«ιΨ≥ΆΤάμΡΘ–ΆΘ®LRMΘ©ΓΘ
‘ΎΤΏΗω≥ΛΈΡ±Ψ DocQA ΜυΉΦ≤β ‘÷–Θ§±μœ÷≥§‘Ϋ o3-mini ΚΆ Qwen3-235B-A22B Β»ΤλΫΔΡΘ–ΆΘ§”κ Claude-3.7-Sonnet-Thinking œύΒ±ΓΘ
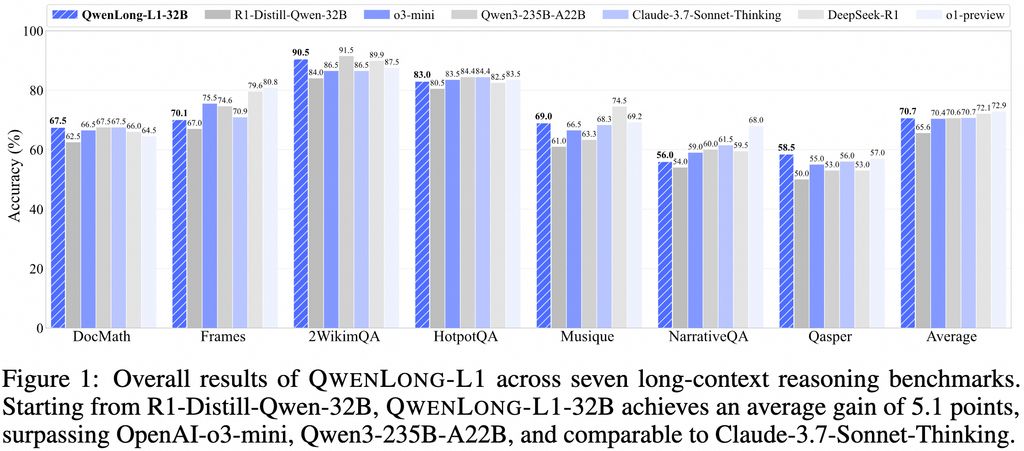
QwenLong-L1-32B ΡΘ–ΆΉν¥σΒΡΝΝΒψΘ§‘Ύ”Ύ…œœ¬ΈΡ¥ΑΩΎΉνΗΏ÷ß≥÷ 131072 Ηω tokensΓΘΗΟΡΘ–ΆΜυ”Ύ QwenLong-L1 ΩρΦήΩΣΖΔΘ§≤…”ΟΝΥœ»ΫχΒΡ GRPOΘ®Group Relative Policy OptimizationΘ©ΚΆ DAPOΘ®Direct Alignment Policy OptimizatioΘ©ΥψΖ®Θ§ΫαΚœΜυ”ΎΙφ‘ρΚΆΜυ”ΎΡΘ–ΆΒΡΜλΚœΫ±άχΚ· ΐΘ§œ‘÷χΧα…ΐΝΥΡΘ–Ά‘Ύ≥Λ…œœ¬ΈΡΆΤάμ÷–ΒΡΉΦ»Ζ–‘ΚΆ–߬ ΓΘ
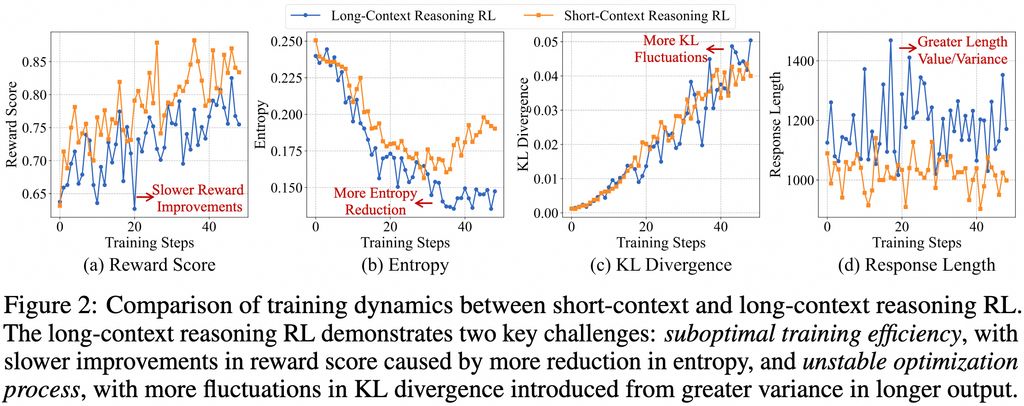
ΨΏΧεΕχ―‘Θ§Ά≈Ε”‘ΎΦύΕΫΈΔΒςΘ®SFTΘ©ΫΉΕΈΫ®ΝΔ“ΜΗωΈ»ΫΓΒΡ≥θ Φ≤Ώ¬‘Θ§ΥφΚσ≤…”ΟΩΈ≥Χ“ΐΒΦΒΡΖ÷ΫΉΕΈ«ΩΜ·―ßœΑΦΦ θά¥Έ»Ε®≤Ώ¬‘―ί±δΘ§≤ΔΫαΚœΡ―Ε»Η–÷ΣΒΡΜΊΙΥ≤…―υ≤Ώ¬‘ά¥ΦΛάχ≤Ώ¬‘ΧΫΥςΓΘ
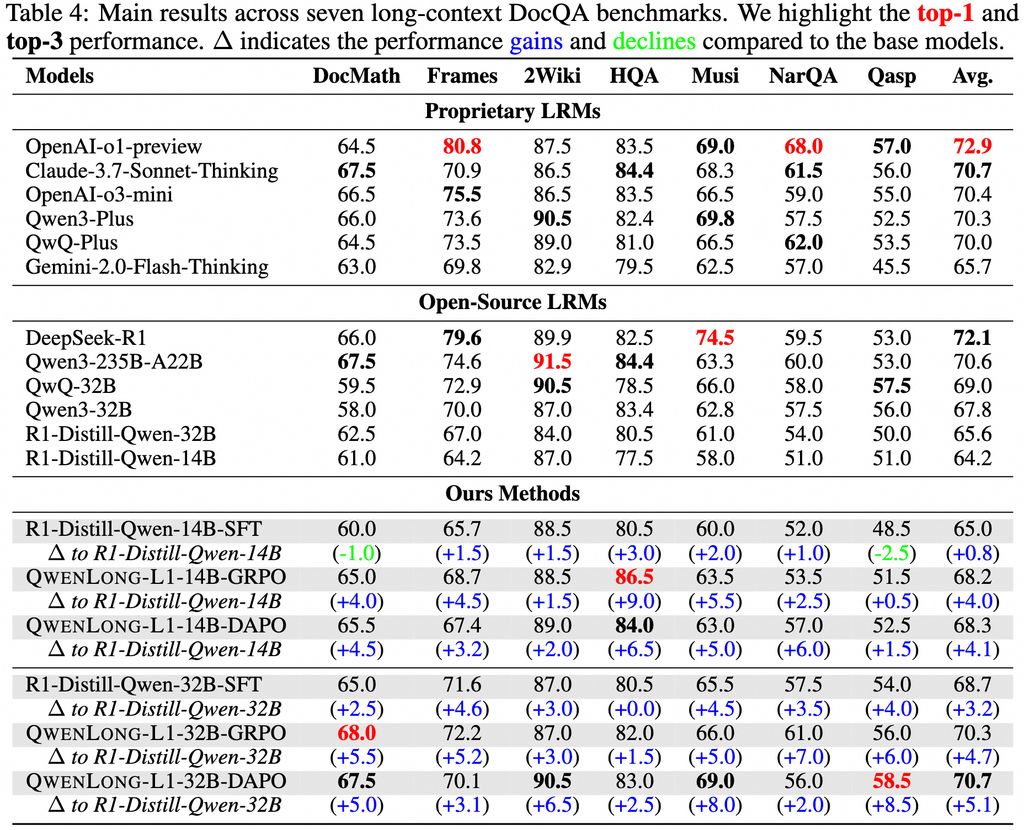
≥ΐΝΥΡΘ–Ά±Ψ…μΘ§ΑΔάοΜΙΖΔ≤ΦΝΥ“ΜΧΉ’κΕ‘≥ΛΈΡ±ΨΆΤάμΈ ΧβΒΡΆξ’ϊΫβΨωΖΫΑΗΓΘΗΟΖΫΑΗΑϋΚ§ΥΡΗωΚΥ–ΡΉιΦΰ: ΗΏ–‘ΡήΒΡ QwenLong-L1-32B ΡΘ–ΆΓΔΉ®Ο≈”≈Μ·ΒΡ―ΒΝΖ ΐΨίΦ·ΓΔ¥¥–¬ΒΡ«ΩΜ·―ßœΑ―ΒΝΖΖΫΖ®Θ§“‘ΦΑ»ΪΟφΒΡ–‘ΡήΤάΙάΧεœΒΓΘ