谷歌研究院日前推出了一款名为 Lumiere 的“文生视频”扩散模型,主打采用自家最新开发的“Space-Time U-Net”基础架构,号称能够一次生成“完整、真实、动作连贯”的视频。

▲ 图源 谷歌官方新闻稿(下同)
谷歌表示,业界绝大多数“文生视频”模型无法生成时间长、质量佳、动作连贯逼真的内容,这是因为此类模型通常“分段生成视频”,首先产生几张关键帧,接着用“时间超级分辨率(Temporal Super-Resolution)”技术,生成关键帧之间的视频文件,这种方法虽然能够节省 RAM,但难以生成“连贯逼真”的视频。
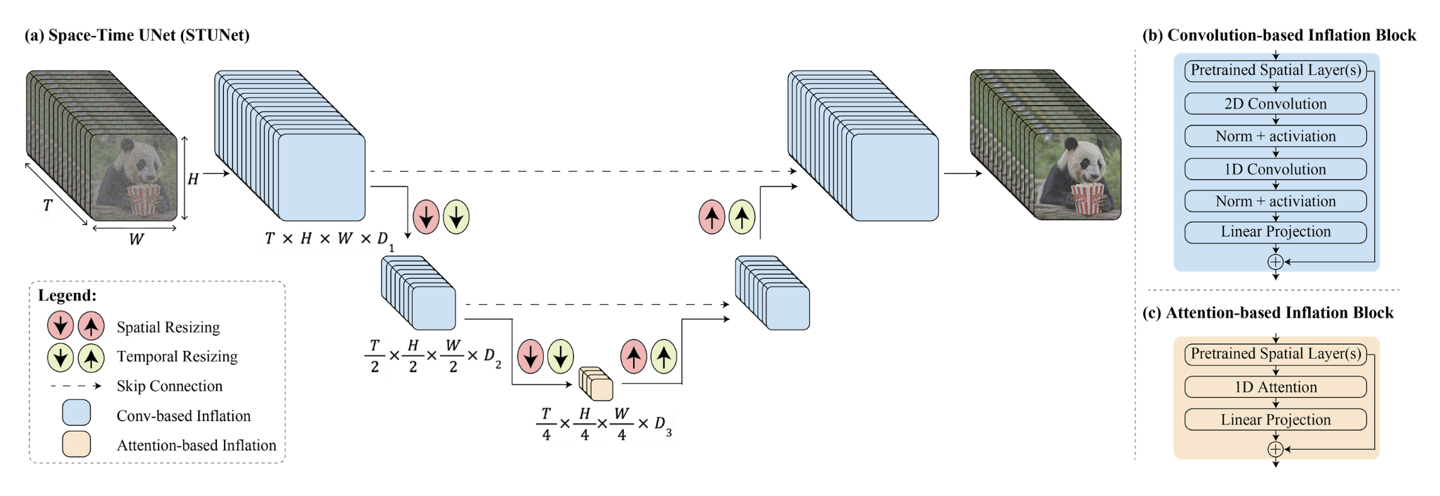
谷歌提到,他们的新模型 Lumiere 相对于业界模型最大的不同是采用了全新“Space-Time U-Net”基础架构,该架构能够在空间和时间上同时“降采样(Downsample)”信号,从而在“更紧凑的时空中进行更多运算”,令 Lumiere 生成持续时间更长、动作更连贯的视频。
Lumiere 一次可以生成 80 帧视频(16FPS 下 5 秒视频 / 24FPS 下约 3.34 秒视频),虽然这一数据看起来很短,不过研究人员提到,5 秒视频长度实际上“已经超过大多数媒体作品中的平均镜头时长”。

除了应用“Space-Time U-Net”基础架构外,谷歌还介绍了 Lumiere 的基础特性,该 AI 建立在一个经过预先训练的“文生图”模型基础上,研究人员首先让基础模型生成视频分帧的基本像素草稿,接着通过空间超分辨率(SSR)模型,逐步提升分帧分辨率及细节,并利用“Multidiffusion”通用生成框架提升模型稳定性,从而保证了最终输出的视频一致性和连续性。