近日,苹果研究人员开发出一种训练图像描述生成AI模型的新方法,新模型能给出更精准详细的描述,且模型规模远小于现有同类模型。

在一项名为《RubiCap:Rubric-Guided强化学习用于密集图像描述生成》的新研究中,苹果研究团队与威斯康星大学麦迪逊分校合作,构建了一个密集图像描述生成模型的新框架,在多个基准测试中取得了领先成果。密集图像描述生成旨在为图像内每个元素和区域生成详细描述,而非单一整体概述,能让人更深入理解图像场景,可用于训练视觉语言和文本转图像模型,提升图像搜索和辅助工具等功能。

研究人员指出,当前训练密集图像描述生成模型的AI方法存在明显不足。标注高质量专家级数据成本高昂,虽可用强大的视觉语言模型生成合成描述,但监督蒸馏得到的输出多样性有限、泛化能力弱,强化学习虽能克服这些局限,但在开放式描述生成中难以应用。
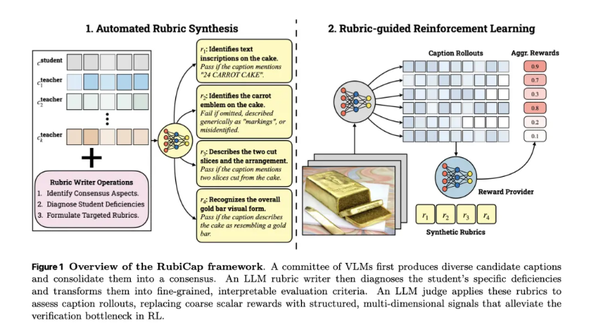
为此,研究团队提出新框架。他们从PixMoCap和DenseFusion-4V-100K两个训练数据集中随机抽取50000张图像,用Gemini 2.5 Pro、GPT-5等现有视觉语言模型为每张图像生成多个描述选项,同时让RubiCap框架下的待训练模型生成自身描述。接着,RubiCap用Gemini 2.5 Pro分析图像、候选描述和模型自身输出,确定评判标准,再由Qwen2.5-7B-Instruct根据标准打分,为训练提供奖励信号。
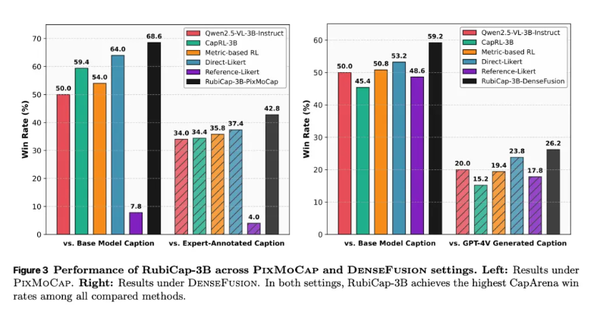
最终,研究团队生成了RubiCap-2B、RubiCap-3B和RubiCap-7B三个模型,参数分别为20亿、30亿和70亿。与现有方法相比,它们表现出色,甚至超越了参数多达720亿的模型。在盲排名评估中,RubiCap-7B在所有模型中排名第一,幻觉惩罚最低、准确性最强。研究还表明,30亿参数的小模型在某些基准测试中表现优于更大规模模型,意味着高质量密集图像描述生成模型不一定需要庞大体量。