���ߣ������� ����ΰ ��˼��
ժҪ������5G-A��������ҵ�����̼��٣�XR������ҵ��������������֪��������˸��ߵ�Ҫ�����������ԣ�MCS�����շָ���������RANK����ΪӰ���������ܵĹؼ����أ����Ż����Զ��û����������Ч�ʾ�������Ӱ�졣�����ۺϷ�����MCS��RANK�Ż������ۻ�������״�Լ������˹�������AI�����Ż�������̽����ͨ������������AI��ģ�����������ܵ�;���������ʵ���Ե���֤���Ż�Ч����
�ؼ�����MCS�������������ԣ���RANK���շָ����������� ����ѧϰ���Ż��㷨����
5G����ĸ����ʡ����ӳٺ���������Ϊ�ڶ���ҵ�������µķ�չ������Ȼ������ʵ�ʲ�������У��źŸ��������Ż�����ս��Ȼ���ڡ������������ԣ�MCS���Ϳշָ���������RANK����Ϊ���������Ż��ĺ���ָ�꣬���Ż����Զ��û��������ʺ�����Ч�����ž��������á�����ͨ���������MCS��RANK��ԭ������Ӱ�����أ�����˹����ܼ���̽���Ż���������ͨ��ʵ���Ե���֤�Ż�Ч����
MCS��RANK�Ż������ۻ���
�����������ԣ�MCS����5G�������������ڱ����û��豸��UE��ҵ����Ч�ʺ������Ĺؼ�������MCS�ĵ��������ŵ������ĺû����ŵ���������ʱ�����ø��߽ĵ��Ʒ�ʽ���ߵı���Ч�ʣ��ŵ������ϲ�ʱ������ø��ͽĵ��Ʒ�ʽ���͵ı���Ч�ʡ�����3GPP TR 38.214Э�飬MCS������֮�������ȷ�Ķ�Ӧ��ϵ��MCSֵԽ�ߣ�����Խ����Ч��Խ�ߡ����磬256QAM��64QAM��MCS Index��Ӧ��ͬ�����ʺ�Ƶ��Ч�ʣ�����ο�Э��3GPP TS 38.214Э���еġ�Table 5.1.3.1-4: MCS index table 4 for PDSCH����
�շָ���������RANK������������ͬ��ʱƵ��Դ�ϣ��ռ���ͬʱ�����������������RANKֵԽ�ߣ�����Խ�ߣ��Ҷ���֮��������Խ�ͣ�����������Խǿ���ն���������2T4R���Ϳտڻ�������ྶ���䣩��RANK��Ӱ�����������ŵ������Ϻ��Ҵ��ڶྶ����ij����£��ն˸�����ȡ�ϸߵ�RANKֵ��
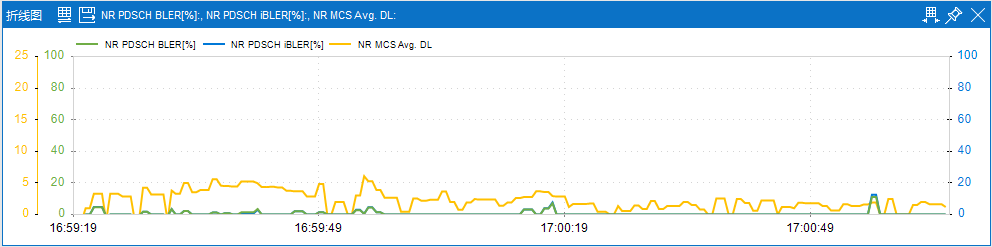
������ͨ������ͬ���������õ�MCS�������������ԣ���RANK���շָ�������������Դ����ģ�飨RRM���㷨����ڲ��죬������������һ�¡���ЩRRM�㷨����SRS��̽��ο��źţ�����������û��豸��UE�����������ŵ�״̬��Ϣ��CSI���ϱ������Ƚ���Լ���վ���ã����㲻ͬMCS/RANK����µ�Ƶ��Ч�ʡ�����һ�����У�MCS�ij�ʼ��������ŵ���������ص���������ΪUEָ����ʼMCSֵ���������UE�ĵ��ȷ�����MCSֵ������ֱ��UE�������ʣ�BLER���ȶ��ں������䣨ͨ��ԼΪ10%������վ��ͨ���Ƚϲ�ͬMCS/RANK��ϵ�Ƶ��Ч�ʣ�ѡ��������Ͻ��е��ȡ�ֵ��ע����ǣ���ͬRANK֮����л��������ض�����ֵ������ͬʱ��ͨ������������Ӱ�첻ͬRANK��Ƶ��Ч�ʣ��������ظ�RANK�������ԡ�
��ǰMCS��RANK�Ż���ʹ��
��ʵ���������绷���У�MCS��RANK���Ż������������ս��������Ϊ�ؼ�����MCS/RANK��ϲ��Ե�ѡ���Լ�����ʣ�BLER���������Ե�ȷ������Щʹ����Ż����Ե�����Ժ���Ӧ������˸��ߵ�Ҫ��
1.MCS/RANK��ϲ���ѡ��
����ͬ���������£���ͬ��MCS/RANK��ϻᵼ��������ͬ��Ƶ��Ч�ʺ������ʱ��֡�������ԣ���RANK��MCS�����������ŵ������Ϻõ��ྶ���䲻��ij�����ͨ�����MCS�ܹ���Ч������������Ч�ʣ�Ȼ�����ϵ͵�RANK���ܻ��������������ʡ��෴����RANK��MCS�����������ڶྶ����ḻ���ŵ�����һ��ij�����ͨ������RANK���������������������ʣ����ܵ�������Ч�ʿ��ܽϵ͡�
��RANK��MCS���ԣ�

��RANK��MCS���ԣ�

��ˣ�MCS/RANK��ϲ��Ե�ѡ����Ҫ����ʵ����������ҵ��������ж�̬��������ʵ���������ܵ����Ż���
2.BLER��������
ѡ��ͬҵ���BLER��������������ͬ����Ϸҵ��ͨ��ѡ���BLER�������ԣ��Լ���ʱ�Ӳ������û����飻����ҳҵ����������ѡ��ϸߵ�BLER�������ԣ������������ʲ����̼���ʱ�䡣
��Ϸ��
��ҳ��

Ȼ����Ŀǰ��û��һ�����ŵ�BLER���������ܹ����������г�����ҵ�����͡���ˣ�BLER���Ե�ѡ����Ҫ�ۺϿ���ҵ�����ͺ��û�������ʵ����ѵ��������ܺ��û����顣
����AI��MCS��RANK�Ż�����
���������һ�ֻ����˹����ܣ�AI����MCS��RANK�Ż�������ּ��ͨ��AI��ģʵ��������ϲ��ԣ��Ӷ������������ܡ��÷����ĺ�����������AI�����Ը��ӵ��������绷�����н�ģ���Ż�����ʵ�ֶ�̬����MCS��RANK���������㲻ͬ�����µ���������

�Ż����裺
1)����Ԥ����
����Ԥ�������Ż������еĹؼ����ڣ���Ҫ��������ƴ�Ӻ��쳣������ϴ�������֡�����ƴ��ͨ������ӿ���ȡ5G����С����Сʱ������ͳ�Ʊ����Լ�ÿ�β����ĺ������������ã���С�����ȹؼ��ֶν���ƴ�ӣ���Щ�ֶξ���Ψһ��ʶС���ҽ��ٸĶ������ԣ��Ӷ�ȷ�����ݵ������Ժ�һ���ԡ�
�쳣������ϴ������Ż�Ŀ���е��쳣���ݽ��й��˺������ڶ�5G�������ݽ��������о������Ƿ�����С��������������Ϊɾ�����ݣ�������LocalOutlierFactor���ֲ��쳣���ӣ�LOF��������������ɸѡ���ܹ�ȡ�����Ч����LOF�㷨��Ϊһ�ֻ����ܶȵľ����㷨������ڴ�ͳ���쳣������㷨�����������ض��ĸ��ʷֲ������ܹ�����ÿ�������������쳣�̶ȣ��Ӷ�����Ч��ʶ��ʹ����쳣���ݡ�
2)���糡����
��������ģ�ı�Ҫ����ҪԴ��������Ŀ��������ȣ�ȫ��ͳһģ������Ч�����ͬ�����²������������졣���磬��Ե�û��ֲ�������С����Ե���ʲ����������Ծ��о�����Ӱ�죬�����ֲ�����ͳһģ�������Եõ���ֿ��ǡ���Σ����ܵ�С����ģ�������ܹ�Ϊÿ��С����ȷ�������Ų���������ʵ�����д��ڽϴ�Ļ������û�������ʹ�������뻰��ģ�͡��Ż�����֮��Ĺ�ϵ��ü�Ϊ���ӣ�����ȷ��ģ�����ڴˣ����IJ��ó���������������������״̬��С������Ϊͬһ�飨������������Ϊÿ����������ͳһ���Ż�������

�ڳ�������ģ�����У����IJ���K-means�����㷨����ר�Ҿ��鶨���Ӱ�����ʵĻ�ͳָ����Ϊ״̬������Ȼ������Щ��ͳָ��������������������죬����������������0��109���ϣ��ŵ�����ָʾ��CQI����ȡֵ��ΧΪ0��15�������ŵ�ȡֵ��Χ����-130��-70֮�䡣�ڼ��������֮��ġ����롱ʱ����ͬ��������ָ���Լ������ĺ����Բ�������Ӱ�졣��ˣ��ڽ��г�������ģ֮ǰ�������ȶԸ���ͳָ������������е�������ȷ�������ȷ�ԡ�Ϊ�ˣ����IJ���StandardScaler������״̬�������б���������ͨ������ָ��ת��Ϊ��ֵΪ0������Ϊ1�������У���Ч����������������Ծ�������Ӱ�졣����㹫ʽΪ��

uΪX��ֵ��sΪX���еı��ͨ��������X����ת��Ϊ��ֵΪ0������Ϊ1��������X'�����������Ǿ����������������㣬�任�����������˳�䣬�µĻ�ͳָ��������һ�¡�
��һ��С��Сʱ������Ϊ����չʾ�����任���̣�

����ͳָ���ֵ������������£�
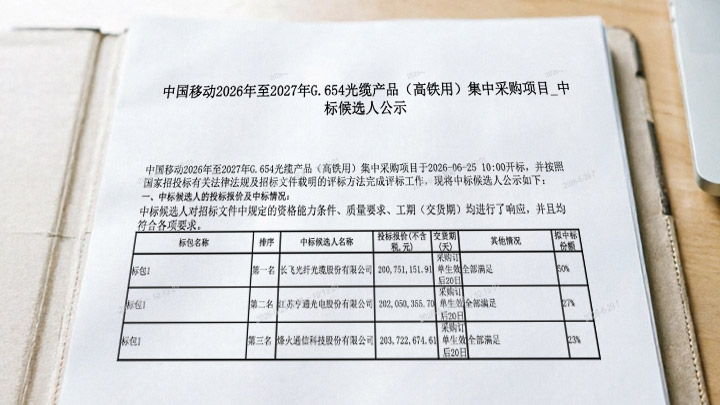
| �л��ɹ��� | ���и��� | RRC�������Դ��� | ƽ��CQI | �������� | �������� | |
| ��ֵ | 99.73 | -112.45 | 1581.00 | 10.88 | 188.06 | 6.66E+07 |
| ��ע�� | 0.40 | 1.05 | 985.65 | 0.87 | 96.98 | 1.39E+08 |
����StandardScaler�任���µ�ָ��X'���£�

�����ݷֲ�����ͼ������ͳָ�����λ��ͬһ�ֲ������ڣ�����ָ�ꡰ���롱Ȩ���൱��
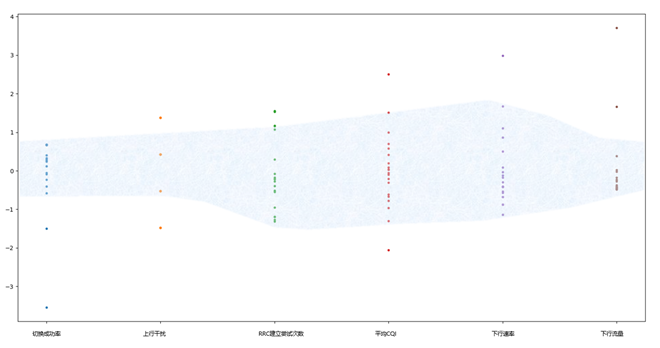
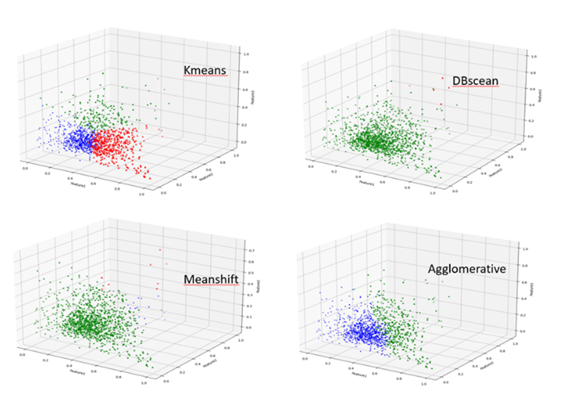
����֮��ʹ�þ����㷨���ж�ά�������֡��ڶ��־����㷨�У���Ҫѡ��һ���㷨�����Ա���ijһ�ೡ����С���������٣�Ӱ����ೡ����ģ��ȷ�ԡ��Գ��õ�������ʽ�Աȿ���Kmeans�㷨���и��ࣨ�أ���С���ȵ��ص㣬������������ɿأ�n_clusters�������ʵ��Ӧ�ã����ʺ���������ʵ�������еij������֡�
| �������� | ʹ�ó��� |
| K-Means | ͨ��, ���ȵ� cluster size���ش�С��, flat geometry��ƽ�漸�Σ�, ����̫��� clusters���أ� |
| Mean-shift | Many clusters, uneven cluster size, non-flat geometry������أ������ȵĴش�С����ƽ�漸�Σ� |
| Agglomerative clustering | Many clusters, possibly connectivity constraints, non Euclidean distances���ܶ�أ������������ƣ���ŷ�Ͼ��룩 |
| DBSCAN | Non-flat geometry, uneven cluster sizes����ƽ�漸�Σ������ȵĴش�С�� |
��ά����ʾ��ͼ�У�Kmeans���������ǵ�Ԥ�ڡ�
ʵ��Ӧ������100��С��������Ϊһ�ֳ������趨����������n_clusters����ʼ�������֡�
3)���ݽ�ģ
���������Ż��ѵ������Ż�Ŀ����С��״̬���������û��������ŵȣ��仯����������仯�����Ż�ƽ������Ϊ����æʱ�����û����࣬���û����ʻ���������½���

������Ż����ѵ�Ҳ��������ڱ仯��״̬�£������Ż�Ŀ����������ģ��ϵ��y=f(��|s)
����״̬s�£���ι���y��a�Ĺ�ϵ���������ǵ������������Ż�Ŀ����Ż������������ԣ���������RBF+MLP�����磬���Ż�����ͨ��RBF������룬����ͳ�ƣ�״̬��ͨ��MLP������룬���Ͻ���������ѵ����

MLPģ�����������������ģ�ͣ�RBFģ����֮���ƣ���ģ�ͽṹ�����ز�����˱仯����MLP�����Ժ���+������滻Ϊ�����Եĸ�˹�������ɴ�RBFģ�;�����ֻ�����ĵ㸽�����������ݸ����е��ص㡣
����tensorflow.keras����������Ƶ�ģ�ͽṹ�ģ�ͣ��������ݷֲ��Ż�ģ�ͳ��Σ�ѧϰ�ʣ�lr�������ݿ��С��batch_size���͵���������epoch������MSE��������ʧ������Ϊģ����ʧ�������۲�MSE�����ٶȣ�ͬʱ�۲�MAE������ֵ����R2�仯���������ѡ������ĵ���������150���£�����ʵ�ѧϰ�ʣ�0.06�������ݿ��С��1024����
4)�����Ƽ�
�����С�����������֡���ģ��ÿ�������µ�С����������ֵ�Ƽ���ͨ������ֵ��������ͨ���ݶ��½�����⣬�����ڸ�άģ�ͣ�ʹ���ݶ��½����������ֵ������һ�������¡� f(x)=( f x1,��, f xn)��
�ڴ�ʹ�������½���������ͨ����������Ա����̶�����ֻ���ʣ����Ա�����ֵ�Ĺ��̡�������һ����ά���Ż�����ͱ��ֽ���˶��һά���Ż����⣬�Ӷ����������ĸ����ԡ�
����ʵ�������в���ֱ�Ӵ��ڹ����ԣ���Ҫͨ����ε��������ٲ����������ϵ������ֵ��Ӱ�졣�Ӷ����֤������������Ż������̶��Ѿ��ﵽ98%���ϣ����������Ż�Ҫ��

�����̶ȣ�����С���������Ƽ��������һ���Ƽ���ͬ�ı����������Ż���������500��С���� �Ż�40�����������Ƽ�20000����������N���Ƽ�������N+1����18000��������ͬ�����N���Ƽ������̶�Ϊ90%��18000��20000����
ʵ���Ե���֤
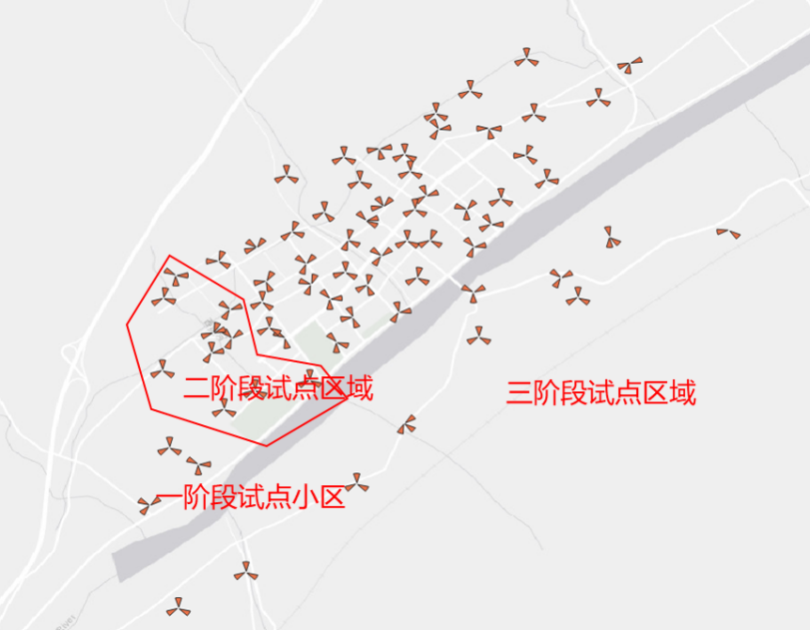
Ϊ����֤������Ļ���AI��MCS��RANK�Ż���������Ч�ԣ�����ѡ����ij���н��ж�����Ż��Ե㡣���������18��3.5G���վ��203��С�����Ż��Ե��Ϊ�����ν��У���ȫ�������Ż�Ч����
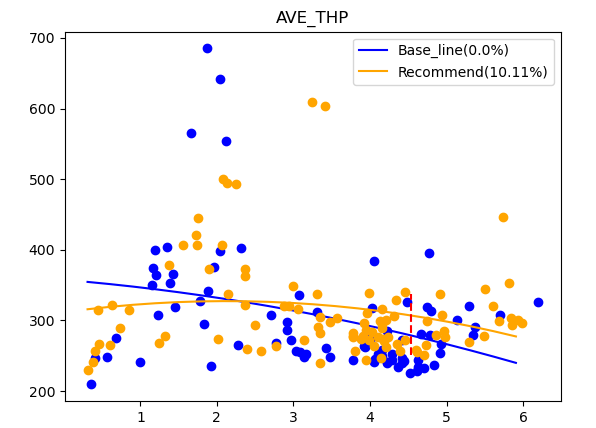
ͨ���Ա��Ż�ǰ�����������ָ�꣬��֤���Ż���������Ч�ԡ��Ż���203��С��������ƽ���������������������������û�������Լ5%����������Լ4%��ֱ��ͳ����������ﵽ7%����һ��ͨ����������Աȣ���������ԼΪ10%����Щ����������Ż������ܹ����������������ܣ�����û��������ʺ����������ʡ�
�Ż�������256QAMռ�Ⱥ���������ռ���������ԣ������ͨ����MCS/RANK�������Ż�����Ч�������û��������ʡ�������ԣ��Ż���������ܹ�����Ч������Ƶ����Դ��ͬʱ����˶��������Ч�ʣ��Ӷ����������������������ܡ�


ʵ���Ե���֤�������������AI��MCS��RANK�Ż������ܹ���Ч�����������ܣ��ر����������û��������ʺ����������ʷ������ͻ�����Ż���������ڲ�ͬ�����¾����ֳ����õ���Ӧ�ԣ���֤�˸÷����Ŀ����Ժ���Ч�ԡ�
������չ��
����ͨ����MCS��RANK�Ż������ۻ�������������������ʵ�������е��Ż�ʹ�㣬�����һ�ֻ����˹����ܵ��Ż��������÷���ͨ������ɸѡ������Ԥ���������������ࡢAI��ģ�Լ�����ֵ�Ƽ��Ȳ��裬ʵ����MCS��RANK�Ķ�̬�Ż���ʵ���Ե���֤�������÷����ܹ����������������ܣ�����û��������ʺ����������ʣ���֤������ʵ��Ӧ���е���Ч�ԡ�
������ˣ�����һЩDZ�ڵĸĽ�����ֵ�ý�һ��̽�������ȣ�����5G����IJ��Ϸ�չ��6G������������δ�����������罫���ٸ��Ӹ��ӵĻ������ߵ�����Ҫ����ˣ���һ���Ż�AI�㷨�����ģ�͵�ȷ�Ժ�Ч�ʣ�����δ���о�����Ҫ������Σ���ϸ�������������ҵ�����ͽ����ۺ��Ż������ܻ��һ������������������ܡ�
���⣬����ڲ�ͬ������ܹ���ҵ���£�ʵ���Ż����Ե�����Ӧ������Ҳ��δ���о���Ҫ����Ĺؼ����⡣������������������Ļ���AI��MCS��RANK�Ż�������Ϊ�����������������ṩ��һ����Ч�Ľ��������δ��������AI�����IJ��Ϸ�չ���������绷�������渴�ӣ���������о������й�����Ӧ��ǰ������Ҫ�����ۼ�ֵ��