随着深度学习技术的快速发展,大模型(如GPT、BERT等)在自然语言处理、计算机视觉等领域取得了显著成果。然而,大模型的参数量和计算量极其庞大,传统的硬件架构或者单台设备(如单个GPU)难以满足其计算需求。大模型的特点如下:
1. DeepSeek-R1模型的参数量高达6710亿,训练过程需要数万台GPU协同工作。
2. 计算需求:大模型的前向传播、反向传播和梯度更新涉及大规模的矩阵运算,单设备无法在合理时间内完成。
3. 内存需求:大模型的参数和中间结果需要大量内存存储,单设备的内存容量有限。
4. 数据需求:大模型的训练需要海量数据,单设备难以高效处理。
为提高大模型的计算效率,必须充分利用矩阵和向量运算的内在并行性。大模型训练的核心流程:前向传播、反向传播和梯度更新,均依赖大规模矩阵计算,这为分布式并行提供了天然优势。目前,主要的并行计算策略包括:
a) 数据并行(Data Parallelism):将训练数据拆分成多个批次或子集,分配到多个设备上执行局部计算。各设备独立计算梯度后,通过梯度同步或聚合机制实现全局参数更新。
b) 模型并行(Model Parallelism):将模型按照参数或模块划分,分布到多台设备上进行计算。当模型单个设备内存难以容纳时,模型并行可以有效扩展计算规模。
c) 流水线并行(Pipeline Parallelism):将模型按照层级或阶段划分成多个片段,各设备依次负责不同层的计算。数据在设备间依次传递,形成一条类似流水线的处理路径,从而在不同处理阶段实现并行性。
分布式计算通过多种并行策略的协同应用,不仅可以突破单设备算力和内存的限制,还能显著加速大规模深度学习模型的训练。
在大模型训练和推理中,GPU虽然是核心计算单元,但其计算能力往往受到数据管理、通信和存储等任务的限制。DPU(Data Processing Unit,数据处理单元)作为一种新型硬件加速器,正在成为大模型训练和推理的重要助力。DPU的出现正是为了解决这些问题:
a) 卸载GPU的计算负担:GPU主要负责矩阵运算等核心计算任务,但数据加载、预处理、通信等任务会占用其资源。DPU可以接管这些任务,通过高速I/O接口直接从存储设备读取数据,减少CPU的介入。大模型训练需要频繁读取和写入大量数据(如模型参数、中间结果、数据集等),传统的存储系统可能成为瓶颈。DPU支持NVMe over Fabric/RDMA等高速存储协议,能够直接从远程存储设备读取数据。让GPU专注于计算,从而提高整体效率。
b) 优化数据预处理与检索:大模型在训练阶段需要大量的预处理(如图像增强、文本分词等),在推理阶段也需要通过知识库进行检索增强,这些操作通过远程访问分布式文件系统来完成。在CPU处理模式下,远端存储访问协议的处理成为瓶颈。我们通过DPU进行远端存储访问协议的卸载,提高数据读写的效率,提供比CPU更高的吞吐量和更低的延迟。
c) 加速分布式训练中的通信:分布式训练中,GPU之间的通信(如梯度同步)会消耗大量时间。DPU可以优化通信任务,支持高效的All-Reduce操作,减少通信延迟。DPU内置专用的通信引擎,使能GPU Direct RDMA,减少CPU的干预,实现超高带宽、低延迟的GPU间通信。
d) 提高能效比:DPU专门针对数据管理和通信任务进行了优化,能够以更低的功耗完成这些任务,从而降低整体能耗
中科驭数作为国内领军的DPU芯片和产品供应商,凭借多年在DPU领域的积累,不断推陈出新,基于公司全自研的国产芯片K2-Pro,推出应用于智算中心的系列产品和方案。

图1 : 中科驭数K2-Pro
K2-Pro芯片的网络处理能力,可以很好的支撑国产化推理集群的各种应用需求,在中科驭数自建的全国产化推理集群中,很好的承担了高通量网络传输,云化流表卸载与分布式资源快速加载的任务。
同时,在AI模型训练方向,中科驭数完全自主研发的RDMA网卡助力数据中心高速网络连接,确保大规模模型的数据传输效率,减少通信延迟,提升整体计算性能。RDMA性能达到200Gbps。释放CPU算力,弥补国产CPU性能不足问题。提供微秒级时延和百G级带宽以及千万级别的IOPS存储访问能力,满足模型计算对数据快速加载的性能要求。
近日,中科驭数基于全国产化CPU、GPU、DPU 三U一体设备本地化部署了DeepSeek模型,系统中通过国产CPU实现整体业务调度与主要服务进程运行,采用国产GPU完成模型推理运算,由中科驭数DPU进行设备裸金属业务管理以及云化网络/存储能力卸载提速。该系统底层采用全国产化的3U一体服务器搭建,在兼顾安全性与低成本的同时,可以高效运行DeepSeek-V3与DeepSeek-R1等多个AI推理模型系统。中科驭数通过这种方式完成多个AI模型适配,打通全国产化三U一体算力底层支撑,能够帮助AI应用在落地过程中实现更好的数据隐私性保护与抵御外部风险的能力,同时也积极推动产业链协同与资源优化整合。
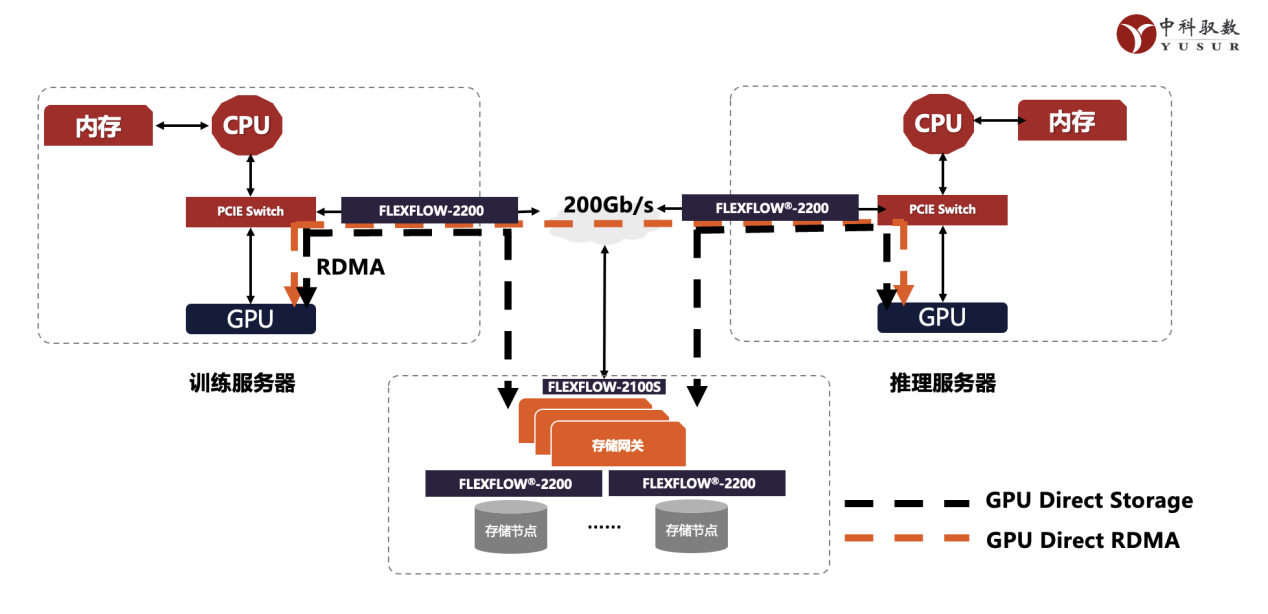
图2 :中科驭数智算中心解决方案
DPU通过卸载GPU的计算负担、优化数据预处理、加速通信和存储任务,正在成为大模型训练和推理的重要助力。驭数的DPU产品凭借其高性能、低功耗和可扩展性,为大模型训练和推理提供了强有力的支持。随着深度学习技术的进一步发展,类似DeepSeek大模型的兴起,以及由此带来对智算资源的大幅优化,给国产GPU和CPU实现高效大模型训练和推理的大规模部署带来巨大可能和期盼。
同时,智算租赁因为DeepSeek模型对于部署资源的优化,让最终从“看着挺美”变成“用着挺美”。很多用户开始尝试租赁智能算资源,这要求智算资源可以按需快速部署。中科驭数的DPU产品,通过流程简化和存储卸载,实现了裸金属部署时间从传统的30分钟优化到3分钟,大大便利了资源的反复利用,也极大地提升了客户订阅的体验。