豆包大模型团队联合北京交通大学、中国科学技术大学共同开发的视频生成实验模型“VideoWorld”今日开源。不同于 Sora 、DALL-E 、Midjourney 等主流多模态模型,VideoWorld 在业界首次实现无需依赖语言模型,即可认知世界。
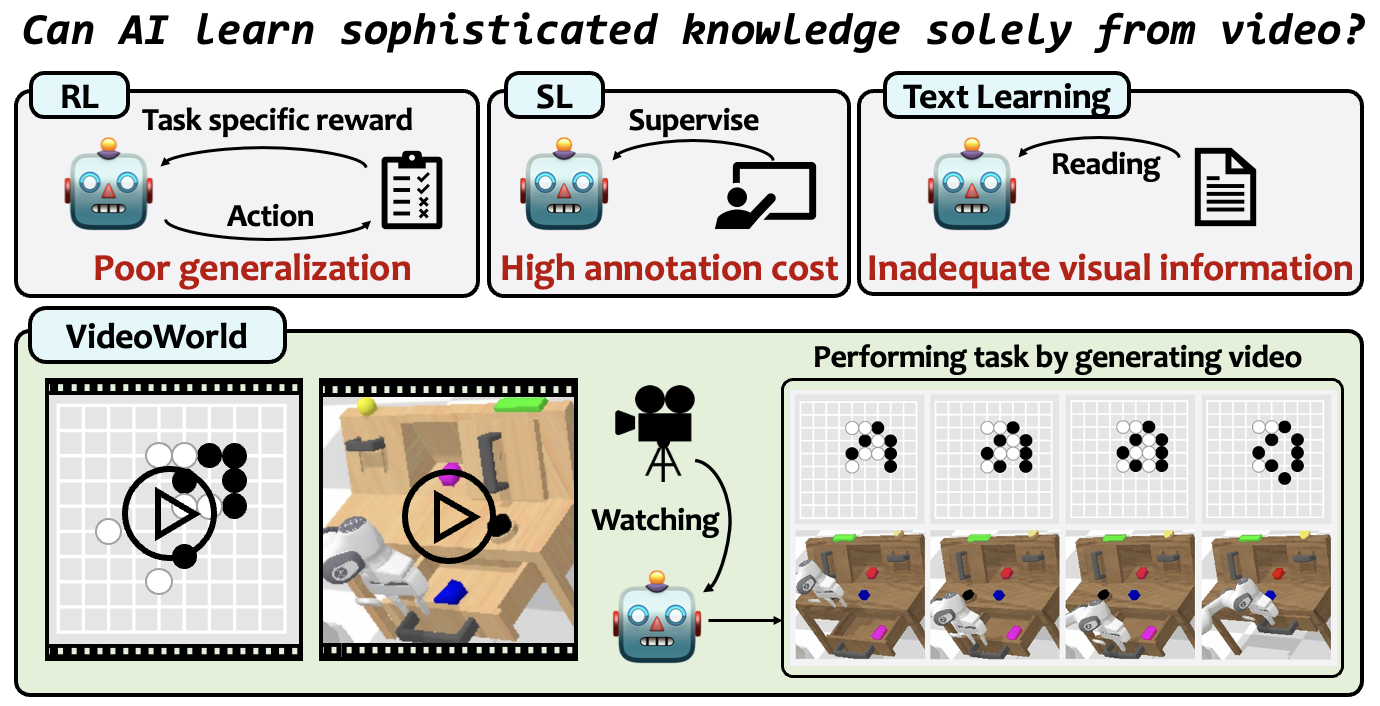
据介绍,现有模型大多依赖语言或标签数据学习知识,很少涉及纯视觉信号的学习。然而,语言并不能捕捉真实世界中的所有知识。例如折纸、打领结等复杂任务,难以通过语言清晰表达。而 VideoWorld 去掉语言模型,实现了统一执行理解和推理任务。
同时,它基于一种潜在动态模型,可高效压缩视频帧间的变化信息,显著提升知识学习效率和效果。在不依赖任何强化学习搜索或奖励函数机制前提下,VideoWorld 达到了专业 5 段 9x9 围棋水平,并能够在多种环境中,执行机器人任务。
附有关地址如下:
论文链接:https://arxiv.org/abs/2501.09781
代码链接:https://github.com/bytedance/VideoWorld
项目主页:https://maverickren.github.io/VideoWorld.github.io