谷歌 DeepMind 团队于 12 月 17 日发布博文,宣布推出 FACTS Grounding 基准测试,评估大型语言模型(LLMs)根据给定材料是否准确作答,并避免“幻觉”(即捏造信息)的能力,从而提升 LLMs 的事实准确性,增强用户信任度,并拓展其应用范围。
数据集
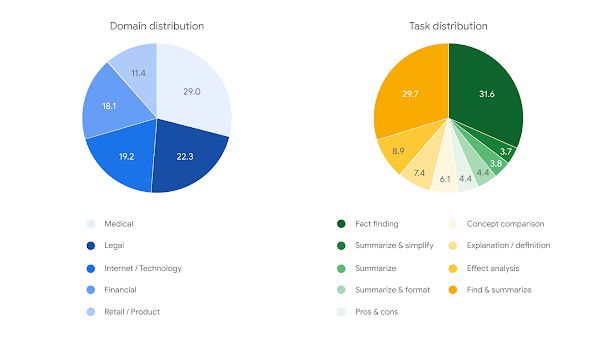
在数据集方面,ACTS Grounding 数据集包含 1719 个示例,涵盖金融、科技、零售、医疗和法律等多个领域,每个示例包含一篇文档、一条要求 LLM 基于文档的系统指令和随附的提示词。
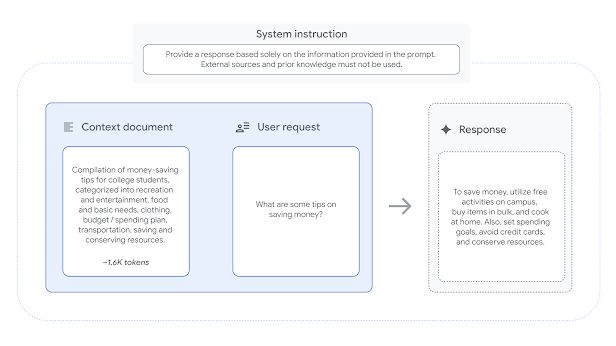
示例文档长度不一,最长可达 32000 个 token(约 20000 字)。用户请求涵盖摘要、问答生成和改写等任务,但不包含需要创造力、数学或复杂推理的任务。IT之家附上演示图片如下:
数据集分为 860 个“公共”示例和 859 个“私有”示例,目前已发布公共数据集供评估使用,私有数据集用于排行榜评分,以防止基准污染和排行榜作弊。
评估方案
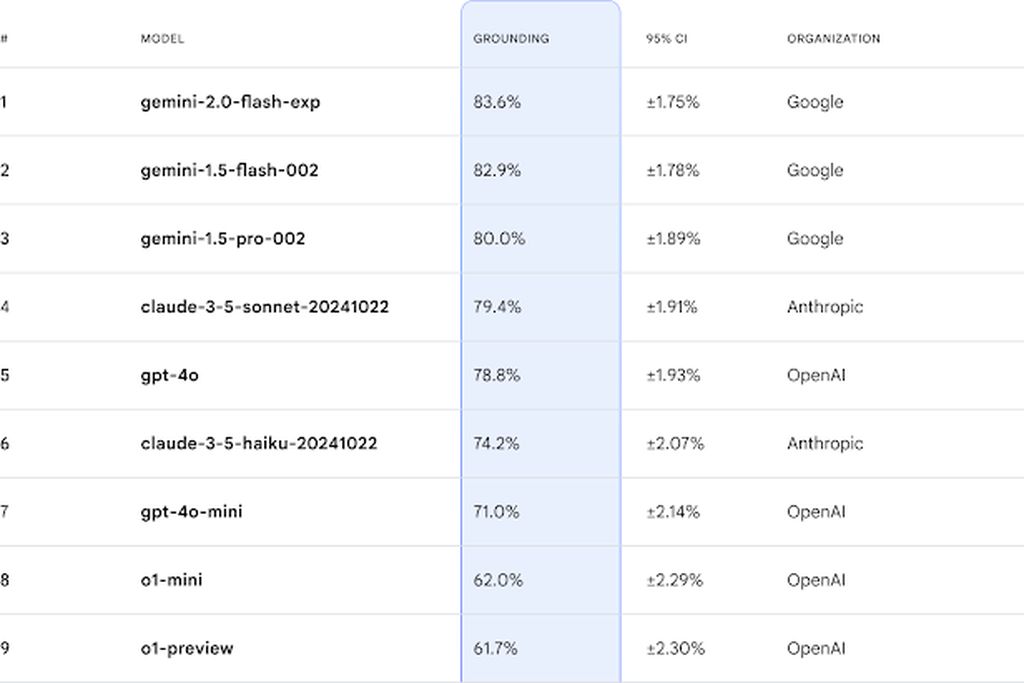
在评估方案上,FACTS Grounding 采用 Gemini 1.5 Pro、GPT-4o 和 Claude 3.5 Sonnet 3 款模型作为评委,评估答案的充分性、事实准确性和文档支持性。
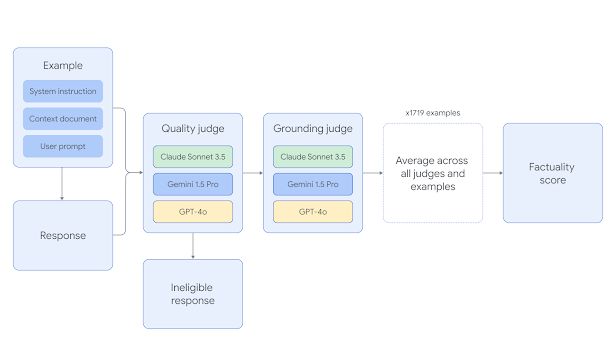
评估分为两个阶段:首先评估响应是否符合资格,即是否充分回答了用户请求;然后评估响应的事实准确性,即是否完全基于所提供的文档,有没有出现“幻觉”,然后基于该模型在所有示例上的平均得分,最终计算得出。
在 FACTS Grounding Benchmark 中,谷歌的 Gemini 模型在事实准确的文本生成方面取得了最高分。