1、什么是超节点?
传统AI服务器由GPU,内存,GPU,外存等组成,互相之间通过服务器内CXL总线互联,对外通信则通过以太网/Infiniband(IB)网络接口。在AI大模型时代,单个GPU显存不足以放下一个几百上千亿的模型,因此会引入模型并行的方式。用于模型并行的几台服务器之间会有非常密集的流量,而以太/IB带宽不足。由此,业界引入了超节点的概念。
所谓AI训练的超节点,是指多个GPU通过总线互联,外观上呈现为一个较大的服务器,NVIDIA的DGX Pod就是一种典型的超节点架构。其实在AI智算时代到来之前,大概十多年前,游戏发烧友口中的“四路Titan”,即在一个机箱中放4块GPU,就是一个小型超节点。那么超节点具体是如何服务于AI大模型训练的呢?
1.1超节点的优势
高互联带宽
当前用于超节点内互联的带宽,一般都在几百GB/s的级别,作为对比,以太网/IB的速率当前主要是200/400Gbps,这两者之间相差一个数量级。因此,超节点内的GPU相互访问要比机外访问的带宽高很多,便于训练时交换参数和同步数据。
简化组网部署
超节点将多个GPU封装在一台服务器之中,内部总线已经连好。因此在搭建大规模AI集群时,使用超节点能大大减少网络部署的复杂度,也降低了后期运维的成本。比如一个千卡集群,如果采用一机16卡的超节点,则变成了64台服务器互联,而不是一千台服务器互联。
1.2超节点承载的AI智算流量
AI大模型训练时,模型大小从百亿到万亿,训练样本是TB量级。因此无论是模型还是样本,对单个GPU来说都太大了,AI大模型训练一定会用到多GPU并行,典型的并行模式如图 1所示。

图 1 AI大模型训练PTD并行示意图
在传统的PTD并行中,Tensor并行(TP)和Pipeline并行(PP)用来拆分模型,Data并行(DP)用来拆分训练样本。这三种并行在逻辑上是相互正交的,即图 1中三维立方体的表述方式。在这个立方体中,X, Y, Z三个方向分别是PP,TP和DP。这也就是说,每个GPU在不同并行时,会和不同的GPU通信,而且通信量也有差异。一般来说,DP和PP的通信量较小,一轮迭代在百MB~GB级别;TP的通信量较大,一轮迭代在百GB级别。
所以,超节点的引入,可以将通信量很大的TP并行放到超节点内,利用高带宽,降低通信开销。而对于PP和DP通信,本身通信量不大,就没有必要再将其放入超节点了。
2、超节点越大越好么?
超节点带来了机内高互联带宽,那自然一个问题就是,超节点规模是否越大越好呢?答案是否定的。
2.1超节点对于中小模型无收益
第一章分析,超节点主要对通信量较大的Tensor并行收益高。Tensor并行主要在百亿以上大模型中存在,对于中小模型,Tensor并行几乎没有。或者有,也只是TP=2/4/8这种规模比较小的情况,当前一机8卡服务器内部总线就能放得下。此时大规模超节点就不能带来收益。
2024年初,OpenAI推出的文生视频大模型Sora又引起了AI领域热烈的讨论。Sora虽然很神奇,能够生成1分钟高质量的视频,但其背后的模型,据推测不超过30亿。30亿的模型现有GPU单卡就能放的下,不需要Tensor并行,从而训练Sora这类的视频生成模型,也不需要超节点的参与。
2.2超节点规模存在甜点
中小模型没收益,那是不是对于大模型,超节点规模就越大越好呢?也不尽然。系统设计除了关注性能外,还要考虑性能提升带来的成本提升。诚然,超节点越大,系统的训练效率肯定越高,但随着规模增长,提升的效率可能无法弥补超节点增大带来的高昂成本。
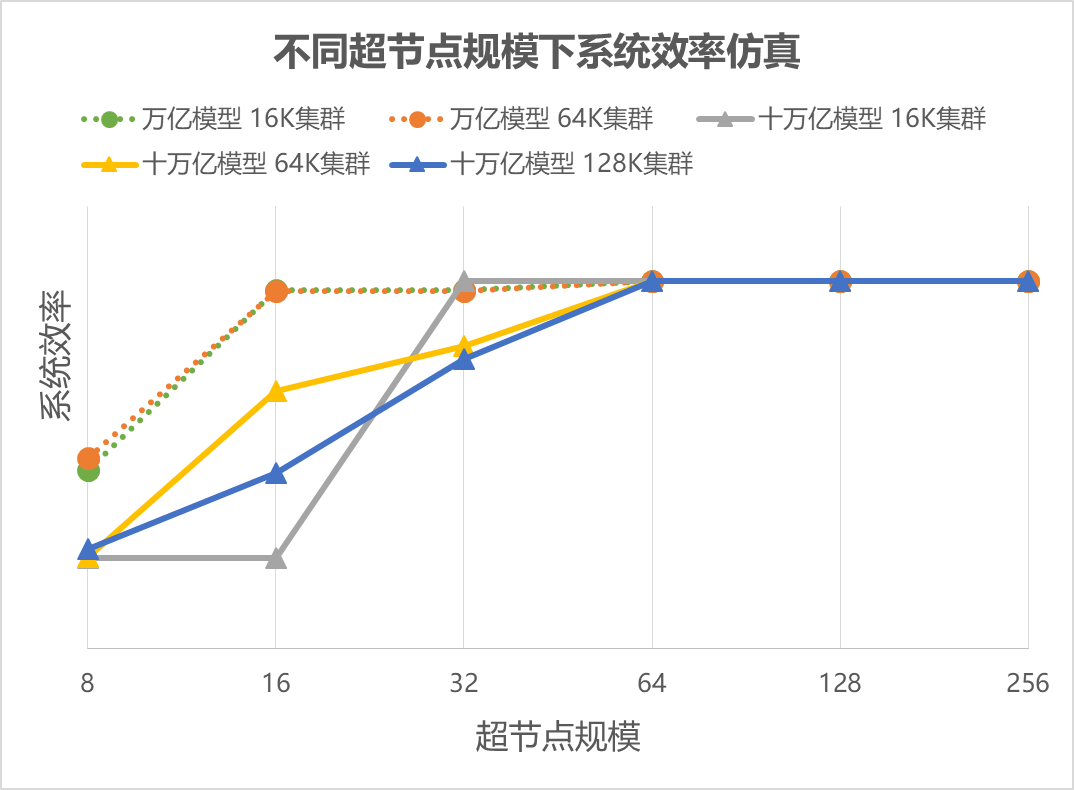
图 2 不同超节点规模下系统效率仿真
图 2 对千亿~十万亿的模型,分别做了不同集群规模,和不同超节点规模下的系统效率仿真。可以看出,对于万亿大模型,超节点甜点在16,十万亿大模型甜点在32~64. 在越过甜点后,继续增加超节点规模,性能提升很低。
2.3规模过大会引入可靠性问题
超节点越来越大时,不仅仅性能提升越来越小,而且可能会带来可靠性问题,导致过大的超节点反而让系统效率出现劣化,即“花更多的钱,效果反而不如从前”。
超节点内的互联是总线类协议,例如传统PCIe,NVIDIA的NVLink等等。总线协议本身不像以太网络协议那样,有复杂的可靠性设计,因为这样会带来很大的协议开销。更何况总线协议设计也不需要这些设计,因为总线是在单个主板上运行,走线都是内部的电路板,本身可靠性很高。
但当超节点规模增大时,单个主板已经放不下太多的GPU,这时,不可避免的要通过光模块和光纤来进行大规模互联。而光模块和光纤的可靠性远不如主板内电路,所以超节点规模太大会让整个系统的可靠性急剧降低。对于AI大模型训练而言,出现故障意味着整网需要重启训练任务,重新加载模型和之前存储的checkpoint检查点,这会使训练成本急剧增加,甚至超过超节点性能提升带来的成本收益。因此可靠性问题不解决,超节点就不那么划算。
2.4超节点部署的实际情况
2023年5月,NVIDIA对外宣称了GH200,超节点规模达到了256,但在实际Amazon Elastic Compute Cloud(Amazon EC2)部署时,规模只有32(GH200 NVL32),如图 3所示. H100的超节点也宣称能达到256,然而DGX-H100仍然维持和前代一样的一机8卡架构。NVIDIA用实际产品证明了,超节点不是越大越好。


图 3 上图:GH200宣称256超节点规模。下图:AWS实际部署的GH200 NVL32,超节点规模为32
3、超节点规模甜点的推导
上面提到了无论是仿真结论,还是NVIDIA实际产品形态,超节点规模都不大。本章节将对超节点性能进行理论建模,半定量的来解释为什么超节点规模存在甜点。
3.1超节点承载不同并行的收益
1.2节中提到,大模型训练的TP, PP, DP三种并行中,TP通信量大,而PP和DP通信量小。所以超节点涵盖TP域收益高,进一步涵盖PP和DP域收益并不高。
这里做一个简单的估算,GPT-3这样的典型大模型,一轮迭代时间在10-30秒。一轮迭代内,一个GPU的TP通信量在500GB左右,PP和DP通信量在10GB左右。如果GPU对外网络是200Gbps,超节点内网络(使用NVLink4数据)带宽450GB/s=3600Gbps. 那么TP通信使用机外网络和超节点内网络耗时分别为20秒和1.1秒;DP或者PP通信使用机外网络和超节点内网络耗时分别为0.4秒和0.02秒。
由此可见,相比于迭代的10-30秒而言,TP通信使用超节点节约的19秒非常可观,而DP/PP通信节约的0.38秒收益就比较低了。所以从成本最经济的角度来说,超节点的甜点就是能覆盖典型大模型的TP域大小。
那么典型模型TP域大小又是多少呢?接下来先推导一下大模型的模型并行总尺度,即需要多大,然后再分析TP和PP分别取值多少比较合适。
3.2模型并行的总尺度
万亿稠密模型,每个参数2字节,总参数量为2TB。训练时额外的梯度、优化器状态是模型参数量的7倍,这部分是静态显存占用开销。除此之外,还有动态显存用于存储计算时的中间变量,主要是正向计算的激活值。一个合理的估算是模型参数量的十倍,即10*2TB=20TB的数据量。当前典型GPU NVIDIA A100的显存标称为80GB,实际可以利用在70GB左右,因此需要300张卡才能完整放下一个万亿模型,即. 而对于十万亿模型,.
3.3超节点的甜点——最佳TP域大小估算
问题可以转变为:大模型参数给定,系统总卡数N给定,给定,因此DP也是一个定值, . 若训练时的batch size和sequence length也给定,那么TP取值为多少时,系统的一轮迭代时间最短?
典型模型训练中,PP和DP占据的时间较短,而且通常可以被计算掩盖。那么一轮迭代中,时间主要由三部分构成:计算时间,TP时间,和PP带来的气泡大小。下面分别分析
在给定上述参数后,一轮迭代中系统总的计算量就确定了,计算公式是 ,这个值再除以N,即得到一张GPU上的计算量,这是个和TP, PP无关的数值。记单卡计算时间为常数C1.
一轮迭代TP的通信量正比于每个mini-batch样本数目,即batch size/DP,也正比于要进行多少次TP,这个和一张GPU上存储的大模型层数相关,可以通过L/PP得到,L是大模型总共的层数。所以TP通信量反比与DP和PP,这相当于正比于TP,因为 是个定值。记单卡TP时间为, C2为常数。
迭代中气泡大小和计算时间的比值,称作系统的bubble ratio. 它等于PP除以一个mini-batch中,micro-batch的数目。后者在micro-batch设定为1时,等于batch size/DP,DP固定时该值固定。所以气泡占用时间正比于PP,记为, C3为常数。
于是系统一轮迭代时间Time为:
根据平均值不等式,在给定时,如果满足,则Time取极小值,即一轮迭代时间最优化。此时, A为给定的数值。
关于C2和C3的推导,本文从略,这里给出对于典型大模型, 在0.4~1之间。那么对于万亿模型,A=300,TP=11~17;十万亿模型,A=3000,TP=35~55. 这和2.2节仿真结果,万亿模型超节点16,十万亿模型超节点32~64,是一致的。
4、谷歌曾经提出过关于超节点收益的公式
谷歌在推出TPUv5 multislice工作时,发表了一篇文章《How to scale AI training to up to tens of thousands of Cloud TPU chips with Multislice》。文章中提出:集群算力规模正比于:1)Global Batch Size, 2)单芯片跨超节点带宽,3)超节点内芯片数目。
这篇文章提出后,引起了学术界和业界热烈的讨论。大家普遍认为:做大超节点规模,做大网络带宽,就可以提升训练模型的理论上限算力。然而,上面分析得出,超节点并不是越大越好。规模过大时,不仅有可靠性问题,也会让性能越过甜点,出现规模继续增大但性能不再提高的情况。那么谷歌的推论问题出在哪里呢?
4.1算力规模公式介绍
这里对文章中公式进行简单推导:

其中,模型Global Batch Size固定,模型的Mini Batch Size由单芯片的算力和带宽之比决定,这个数在公式中定义成为了DCN arithmetic intensity. 具体来说,单芯片一秒钟能算m个样本,一秒钟能传输n个样本,则理想的Mini Batch Size= m/n. 这样可以充分利用计算和通信资源,互相不成为瓶颈。超节点内整体考虑时,算力和带宽都会乘以超节点内芯片数,Mini Batch Size的比值不变。
有了Global Batch Size和Mini Batch Size后,整网数据并行的数目,即超节点数目Total number of ICI domains required = Global Batch Size / Mini Batch Size. 然后再乘以超节点内算力,消去单芯片算力(FLOPs/chip)后,得到最后一行蓝色的公式。
4.2公式的假设和问题

该公式假设一个超节点恰好放一个完整模型。在这个假设下,超节点数目=数据并行份数(DP值)=Global Batch Size/Mini Batch Size,即图中蓝色框所示。那么此时超节点大小等于,因此较大。
实际上,可以一个超节点内放多个模型;也可以多个超节点共同放一个模型,互相之间用pipeline并行(PP)。PP对带宽需求远不如TP,因此DCN带宽能够胜任。这也是3.1节中分析的,超节点放下TP即可,再把PP放入,收益并不高。
4.3对谷歌公式总结
根据上述分析,公式假设超节点至少要放下,但经过前面建模分析,超节点的甜点放下TP就能满足要求。
其实可以从另一个角度理解这个公式,除了超节点规模外,公式中提出集群规模还正比于机外网络带宽。所以,如果超节点不需要很大,那反过来应该需要较大的DCN/参数面网络带宽,来提升集群的算力性能。简言之,相对做大超节点,降低参数面带宽的路;合理的超节点规模+较大的参数面网络带宽才是更合理的路线。
5、结论
超节点通过在主机内高速总线互联,以提升大模型训练Tensor并行通信效率。超节点的价值在于增大全局通信带宽的成本太高,转而通过增加局部带宽来达到最大的收益。
超节点规模并不是越大越好,首先中小模型不需要超节点参与,对于大模型而言,仿真显示超节点的规模存在最优的“甜点”,规模过大性能不再提升,反而会造成成本浪费。当前千亿~万亿模型,超节点设计在16比较经济,AWS购买的GH200也只增加到了32. 这是因为未来十万亿模型,超节点设计在32~64也足够了。过大的超节点在系统设计时不可避免会遇到可靠性下降的问题。
因此,虽然超节点对于AI大模型训练很有用,但一个高质量的AI系统不仅仅是把超节点做大就行,还需要将运行模型大小,成本边际效益,超节点外以太网带宽等因素综合考虑。
参考信息:
https://openai.com/research/video-generation-models-as-world-simulators
https://mp.weixin.qq.com/s/ZpZJ9XpbH8QYarMbxXM6SQ
https://blogs.nvidia.cn/2023/11/28/aws-nvidia-strategic-collaboration-for-generative-ai/
https://cloud.google.com/blog/products/compute/using-cloud-tpu-multislice-to-scale-ai-workloads